|
|
Perl正規表現の使い方 正規表現の基本 |
H.Kamifuji . |
- はじめに
結合演算子(=~)を使った正規表現の基本的な使い方を確認します。
当ページでは、Linux CentOS7 の Gnome で動作テストしています。
- 目 次
- 正規表現の利用方法
[ 目次 ]
まず最初に正規表現がどのような時に利用されるのかを確認しておきます。
例えば変数に格納された文字列が、ある文字列と一致するかどうかを調べるには次のように記述しました。
my $str = "Hello"; if ($str eq "Hello"){ print "文字列はHelloです\n"; }else{ print "文字列はHelloではありません\n"; }※「eq」演算子については「関係演算子」を参照して下さい。
このサンプルでは変数に格納された文字列と「Hello」と言う文字列が完全に一致しますので「文字列はHelloです」が出力されます。
それでは変数に格納された値に「e」と言う文字が含まれているかどうかを調べるにはどうすればいいでしょうか。先ほどと同じように「eq」演算子を使って記述してみます。
my $str = "Hello"; if ($str eq "e"){ print "文字列に「e」を含みます\n"; }else{ print "文字列は「e」を含みません\n"; }今度のサンプルでは「文字列は「e」を含みません」が出力されてしまいます。それは「eq」演算子が演算子の左辺と右辺が完全に一致している場合にだけ真(true)を返しためです。変数「$str」に格納された値は「e」と言う文字を含みはしますが「e」ではありません。
このように文字列の中に指定した文字が含まれているかどうかを調べる時に正規表現は使用されます。詳しい記述方法は次のページ以降に確認して行きますが、正規表現を使うことで次のように記述することが出来ます。
my $str = "Hello"; if ($str =~ /e/){ print "文字列に「e」を含みます\n"; }else{ print "文字列は「e」を含みません\n"; }ここで「/e/」と書かれた部分が正規表現での記述となっています。「e」が一致する条件を示すパターン、パターンを囲んでいる「//」がパターンマッチ演算子、パターンと対象の値がマッチしているかどうかを調べる「=~」が結合演算子です。今回の場合は「e」が含まれているかどうかを調べ、含まれている場合は真(true)を返します。
正規表現として記述できるパターンは、単なる文字列が含まれているかどうかだけではなく、行頭にあるものや、ある文字が1回以上続けて記述されているものなど複雑な条件が指定できるようになっています。では次のページ以降で正規表現の使い方を詳しく見ていきます。
では簡単なプログラムで確認して見ます。
test1-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 正規表現の利用方法 use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my $str = "Hello"; if ($str eq "Hello"){ print "文字列はHelloです\n"; }else{ print "文字列はHelloではありません\n"; } if ($str eq "e"){ print "文字列に「e」を含みます\n"; }else{ print "文字列は「e」を含みません\n"; } if ($str =~ /e/){ print "文字列に「e」を含みます\n"; }else{ print "文字列は「e」を含みません\n"; }上記を「test1-1.pl」の名前で保存してから次のように実行して下さい。

Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Ini]$ perl test1-1_u.pl | nkf -w 文字列はHelloです 文字列は「e」を含みません 文字列に「e」を含みます [xxxxxxxx@dddddddddd Ini]$
- 結合演算子(=~)
[ 目次 ]
正規表現ではパターンを定義し、対象の文字列がそのパターンに当てはまる(マッチする)かどうかを調べるために使います。そこでパターンにマッチしているかどうかを確認するために使用されるのが結合演算子「=~」です。
書式は次のようになっています。
左辺 =~ /パターン/
「=~」演算子は左辺に記述した文字列が右辺に設置した正規表現を使って記述されたパターンにマッチするかどうかを調べます。マッチした場合は式全体として真(true)を返し、マッチしない場合には偽(false)を返します。
真又は偽を返しますのでif文の条件式やwhile文の条件式として使用することが出来ます。
my $str = "Hello"; if ($str =~ /e/){ print "文字列に「e」を含みます\n"; }上記の場合は変数「$str」に格納されている値が、「=~」演算子の右側に記述されているパターンとマッチしているかどうかを評価し、マッチしていればif文の条件式は真(true)となります。
結合演算子の省略
結合演算子を使ってパターンとの比較が行われる左辺の値がデフォルト変数「$_」の場合、左辺の変数と結合演算子を省略することが可能です。
if ($_ =~ /e/){ print "文字列に「e」を含みます\n"; }上記は単に次のように記述することが出来ます。
if (/e/){ print "文字列に「e」を含みます\n"; }デフォルト変数が対象の場合はこのようにシンプルに記述することが出来ます。
では簡単なプログラムで確認して見ます。
test2-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 結合演算子(=~) use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; print "入力して下さい\n"; while(
上記を「test2-1.pl」の名前で保存してから次のように実行して下さい。){ if (/q/){ print "一致しました。終了します\n"; exit(0); } print "入力して下さい\n"; }
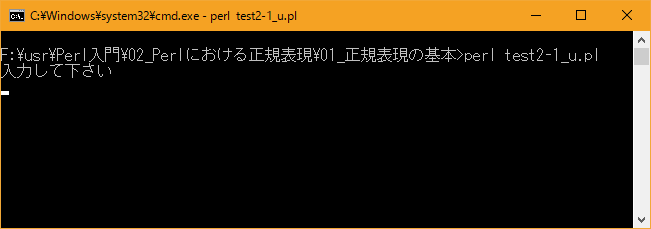
プログラムを実行すると標準入力からの入力待ちとなります。今回は入力した値に「q」と言う文字が含まれるまで繰り返し入力が求められます。
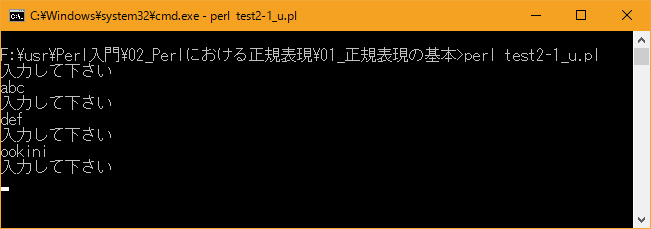
入力した値に「q」と言う文字が含まれるていればパターンにマッチしてプログラムは終了します。

Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Ini]$ perl test2-1_u.pl 入力して下さい
プログラムを実行すると標準入力からの入力待ちとなります。今回は入力した値に「q」と言う文字が含まれるまで繰り返し入力が求められます。
[xxxxxxxx@dddddddddd Ini]$ perl test2-1_u.pl 入力して下さい abc 入力して下さい def 入力して下さい ookini 入力して下さい
入力した値に「q」と言う文字が含まれるていればパターンにマッチしてプログラムは終了します。
[xxxxxxxx@dddddddddd Ini]$ perl test2-1_u.pl 入力して下さい abc 入力して下さい def 入力して下さい ookini 入力して下さい opqop 一致しました。終了します [xxxxxxxx@dddddddddd Ini]$
- パターンの記述方法
[ 目次 ]
どのような文字列と一致させたいのかを指定するのがパターンです。正規表現とはこのパターンの記述方法について定義したものとも言えます。パターンの定義は次のように「/」と「/」の間に挟んで指定します。
/パターン/
パターンの中には単純な文字列から様々な特殊な意味を持った記号を記述することが可能です。詳しい解説は別のページで行いますので、ここでは単なる文字列を指定した場合で考えてみます。
例として1文字だけを記述した場合です。
/a/
この場合は対象の文字列に「a」が含まれていればマッチします。文字列の中のどの位置にあるのかは関係ありません。またパターンでは大文字と小文字は区別されますので「A」が含まれていてもマッチしません。
よって次のような文字列の場合にマッチします。
abc
This is a pen.
yahoo
次に複数の文字をを記述した場合です。
/abc/
この場合は対象の文字列に「abc」が含まれていればマッチします。「a」「b」「c」の3つの文字が含まれていればという意味ではなく、「abc」と言う3つの文字が連続して記述されたものが含まれているかどうかで判別されます。
よって次のような文字列の場合にマッチします。
abc
toabcdepplo
oojkiabc
では簡単なプログラムで確認して見ます。
test3-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# パターンの記述方法 use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my $str = "abcdedcba"; print "対象:$str\n"; if ($str =~ /cda/){ print "cdaにマッチします\n"; }else{ print "cdaにマッチしません\n"; } if ($str =~ /cde/){ print "cdeにマッチします\n"; }else{ print "cdeにマッチしません\n"; }上記を「test3-1.pl」の名前で保存してから次のように実行して下さい。

Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Ini]$ perl test3-1_u.pl | nkf -w 対象:abcdedcba cdaにマッチしません cdeにマッチします [xxxxxxxx@dddddddddd Ini]$
- パターンマッチ演算子(m//)
[ 目次 ]
前のページでパターンを定義する場合には「/」と「/」の間に挟んで指定すると記述しました。この「//」はパターンマッチ演算子と呼ばれるもので、演算子としては「m//」と言うのが正式な記述方法です。
m/パターン/
ここで「/」は区切り文字(デリミタ)として使用され、パターンマッチ演算子は「m」+「区切り文字」+パターン+「区切り文字」と言う構成になります。デフォルトの区切り文字は「/」を使用していますが「/」を使用した場合だけ先頭の「m」を省略して「/パターン/」として使用することが出来ます。
m//演算子の区切り文字
区切り文字はペアになっている記号の文字であればどのような区切り文字でも構いません。
m!パターン! m@パターン@ m%パターン%
また次の4つについては同じ記号でなくても使用することが出来ます。
m(パターン) m{パターン} m[パターン] m<パターン>
パターンの中にある区切り文字のエスケープ
パターンの中に区切り文字と同じ文字が含まれていた場合は「\」記号を使ってエスケープします。例えば「abc/def」と言うパターンを定義したい場合には次のように記述します。
/abc\/def/
もしエスケープする文字が多いようであれば別の区切り文字を使った方がシンプルに記述できます。
m(abc/def)
では簡単なプログラムで確認して見ます。
test4-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# パターンマッチ演算子(m//) use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my $str = "abcdedcba"; print "対象:$str\n"; if ($str =~ m@cde@){ print "cdeにマッチします\n"; }else{ print "cdeにマッチしません\n"; } $str = "ab/ddef/edf/abc"; print "対象:$str\n"; if ($str =~ m(ef/e)){ print "ef/eにマッチします\n"; }else{ print "ef/eにマッチしません\n"; }上記を「test4-1.pl」の名前で保存してから次のように実行して下さい。
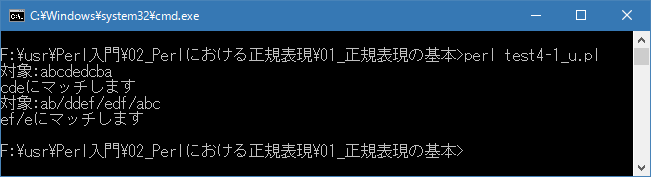
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Ini]$ perl test4-1_u.pl | nkf -w 対象:abcdedcba cdeにマッチします 対象:ab/ddef/edf/abc ef/eにマッチします [xxxxxxxx@dddddddddd Ini]$
- パターンの中のエスケープ処理
[ 目次 ]
パターンの中には任意の文字を記述することが出来ますが、メタ文字と呼ばれる特殊な用途で使用される文字にはエスケープ処理が必要となります。
\ * + . ? { } ( ) [ ] ^ $ - | /これらの文字はパターンの中で使用されると特別な意味を持ちます。そこで単なる文字として扱いたい場合には「\」記号を使ってエスケープ処理を行います。例えば次のように記述します。
\\ \* \|
この中で「/」についてはパターンマッチ演算子の区切り文字を「/」以外にした場合は必要ありません。(パターンマッチ演算子については「パターンマッチ演算子(m//)」を参照して下さい)。
また「-」については[]の中で使用される場合にだけ特別な意味を持つため、[]の中で使用される時にエスケープ処理が必要となります。
エスケープシーケンス
パターンはダブルクオーテーションで囲った文字列と同じように扱われます。その為、次のようなエスケープシーケンスも利用出来ます。
\a 警報音 \n 改行 \r 復帰 \f 改ページ \t 水平タブ \e ESC \ooo 8進数 \xhh 16進数 \cX コントロール文字(\cCならCtrl+C) \l文字 文字を小文字 \u文字 文字を大文字 \L...\E ...を小文字 \U...\E ...を大文字 \Q...\E ...の中のメタ文字をエスケープ
また「$」及び「@」についてはメタ文字としての使用や、パターンの中に変数や配列を展開する時にも使用される文字のため注意が必要です。また詳しい解説は後のページで行います。
他にも特別な意味を持つエスケープシーケンスが用意されていますが、必要になった時に随時解説していきます。
では簡単なプログラムで確認して見ます。
test5-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# パターンの中のエスケープ処理 use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my $str = "[the]"; print "対象:$str\n"; if ($str =~ /\[t/){ print "[t にマッチします\n"; }else{ print "[t にマッチしません\n"; } $str = "ab\tcd"; print "対象:$str\n"; if ($str =~ /b\tc/){ print "b\tc にマッチします\n"; }else{ print "b\tc にマッチしません\n"; }上記を「test5-1.pl」の名前で保存してから次のように実行して下さい。
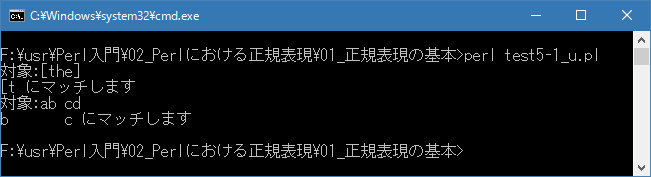
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Ini]$ perl test5-1_u.pl | nkf -w 対象:[the] [t にマッチします 対象:ab cd b c にマッチします [xxxxxxxx@dddddddddd Ini]$
- リリースノート
[ 目次 ]- 2020/10/25 Ver=1.01 JDK_15 で確認
- 2017/03/08 Ver=1.01 初版リリース
- 関連ページ
[ 目次 ]- Perlにおける正規表現
- Perlにおける正規表現 正規表現の基本
事例を参照させていただきました。
- Perlにおける正規表現