|
| Perlプログラム作成の条件分岐 |
H.Kamifuji . |
- はじめに
プログラムは記述した順に実行されるのが基本ですが、変数の値などによって実行する処理を分けたい場合があります。ここでは「if」文及び「unless」文を使い条件に従って処理を分岐する方法について確認します。
当ページでは、Linux CentOS7 の Gnome で動作テストしています。
- 目 次
- if文
[ 目次 ]
プログラムは記述した順に実行されていきます。ただある条件によって処理を分けたい場合もあります。例えば変数の値が正の数ならこちらの処理を行い負の数ならこちらの処理を行うといった場合です。
このように条件に従って処理を分岐させるための使われるのが「if」文です。「if」文の書式は次のようになっています。
if (条件式){ 条件式が真の時に実行する処理1; 条件式が真の時に実行する処理2; }条件式の箇所には「x == 10」や「y > 15」など関係演算子を使った条件式を記述します。この条件が真(true)となる時に「{」から「}」までの文が実行されます。(関係演算子については次のページを参照して下さい)。例えば「変数に格納されている値が正の数なら」とか「変数に格納されている文字列が"国語"と等しかったら」などです。
なお「{」から「}」で囲まれた部分をブロックと呼びます。if文の場合には条件式が真の場合にブロック内に記述された文を実行するということになります。ブロックはプログラムの中である範囲を区分するために使われます。
他のプログラムミング言語では、実行される文が1つの場合はブロック無しで記述できる言語もありますが、Perlでは必ず「{」と「}」で囲ってブロックを記述する必要があります。
実際のプログラム例としては次のようになります。
my $seiseki; $seiseki = 75; if ($seiseki > 60){ print "合格です\n"; print "おめでとう\n"; } print "以上です";今回の例では条件式として変数「$seiseki」に格納されている値が60よりも大きいかどうかを設定しています。条件式が真となるとき、つまり変数の値が60よりも大きい場合に「{」から「}」で囲まれたブロック内の「print "合格です\n";」が実行され、次に「print "おめでとう\n";」が実行されます。そしてブロックが終わった後の「print "以上です";」が実行されます。
もしも変数に格納されている値が60以下の場合にはブロック内の処理は行われずに、ブロックの後に記述された「print "以上です";」が実行されます。
ブロック
if文でブロックを記述する時には次のように記述しても構いません。
my $seiseki; $seiseki = 75; if ($seiseki > 60) { print "合格です\n"; print "おめでとう\n"; }ブロックの「{」の位置が先ほどのサンプルとは異なっています。これはどちらでも構いません。
なお「if」文の次の行の先頭がインデント(字下げ)されています。これは「if」文の結果によって実行される箇所であるというのを分かりやすくするための慣習として行われていますがインデントは必須ではありません。ただ次のようにインデントしないで記述するとどの行が条件によって実行される行なのか分かりにくくなります。
my $seiseki; $seiseki = 75; if ($seiseki > 60) { print "合格です\n"; print "おめでとう\n"; }では簡単なプログラムで確認して見ます。
test1-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# if文 use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my $seiseki; $seiseki = 75; print "得点 = $seiseki\n"; if ($seiseki > 60){ print "合格です\n"; print "おめでとう\n"; } print "お疲れ様\n"; $seiseki = 47; print "得点 = $seiseki\n"; if ($seiseki > 60){ print "合格です\n"; print "おめでとう\n"; } print "お疲れ様\n";上記を「test1-1.pl」の名前で保存してから次のように実行して下さい。
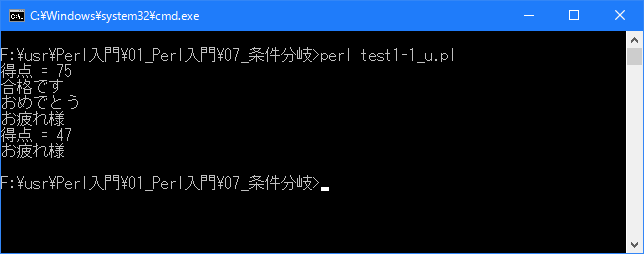
今回は変数に格納した値を変えて、同じ処理を2回繰り返しています。1回目は条件式が真となるためブロック内が実行されますが、2回目は条件式が偽となるためブロック内は実行されません。
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd If]$ perl test1-1_u.pl | nkf -w 得点 = 75 合格です おめでとう お疲れ様 得点 = 47 お疲れ様 [xxxxxxxx@dddddddddd If]$
- 関係演算子
[ 目次 ]
if文などの条件分岐の時には条件式の内容が真か偽かによって処理を分けます。条件式には「xxxと等しい」とか「xxxよりも大きい」などを指定することになります。この条件式の中で使用されるのが関係演算子です。
まずは関係演算子の種類を確認します。
演算子(数値) 演算子(文字列) 記述例 意味 == eq a == b bがaに等しい != ne a != b bがaに等しくない > gt a > b bよりaが大きい >= ge a >= b bよりaが大きいか等しい < lt a < b bよりaが小さい <= le a <= b bよりaが小さいか等しい
関係演算子には数値を比較するための演算子と文字列を比較するための演算子の二種類が用意されています。例えば2つの値が等しいかどうかを判別する場合、数値を比較するには「==」を使い、文字列を比較するには「eq」を使います。結果として真(true)又は偽(false)を返します。
文字列を比較する場合には、両辺の文字列の値を1文字ずつ順に比較していきます。大きいか小さいかの判別は比較する2つの文字列をソートしてどちらが先にくるのかで比較しています。
なお文字列の比較の場合には数値用の演算子を使うことも出来ます。
等しいかどうかの比較
等しいかどうかを比較するには「==」又は「eq」を使います。例えば次のように記述します。
my ($num, $name); $num = 10; if ($num == 10){ print "10と等しい\n"; } $name = "加藤"; if ($name eq "加藤"){ print "加藤です\n"; }この場合は変数「$num」に格納されている値が「10」と言う数値と等しいかどうかを判別します。また変数「$name」に格納されている値が「加藤」と言う文字列と等しいかどうかを判別しています。等しい場合は条件式が「真」、等しくない場合は条件式が「偽」となります。
また等しくないかどうかを比較するには「!=」又は「ne」を使います。例えば次のように記述します。
my ($num, $name); $num = 10; if ($num != 15){ print "15と等しくない\n"; } $name = "加藤"; if ($name ne "伊藤"){ print "伊藤ではありません\n"; }この場合は変数「$num」に格納されている値が「15」と言う数値と等しくないかどうかを判別します。また変数「$name」に格納されている値が「伊藤」と言う文字列と等しくないかどうかを判別しています。等しくない場合は条件式が「真」、等しい場合は条件式が「偽」となります。
大きいかどうかの比較
演算子の右辺と左辺の数値の大きさを比較するには「>」「>=」「<」「<=」を使います。文字列の場合は「gt」「ge」「lt」「le」です。例えば次のように記述します。
my ($num, $name); $num = 10; if ($num > 5){ print "5よりも大きい\n"; } $name = "abc"; if ($name gt "ABC"){ print "ABCより大きい\n"; }この場合は変数「$num」に格納されている値が「5」と言う数値よりも大きいかどうかを判別します。また変数「$name」に格納されている値が「ABC」と言う文字列と比較して大きいかどうかを判別しています。大きい場合は条件式が「真」、大きくない場合は条件式が「偽」となります。
文字列の場合に大きいというのは、2つの値をソートして後に出てくる方が大きい値となります。「a」と「b」なら「b」の方が大きく、「a」と「A」なら「a」の方が大きいです。
では簡単なプログラムで確認して見ます。
test2-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 関係演算子 use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my ($num, $name); $num = 10; if ($num == 10){ print "$num と10は等しい\n"; } $name = "加藤"; if ($name eq "加藤"){ print "$name と加藤は等しい\n"; } $num = 10; if ($num != 15){ print "$num と15は等しくない\n"; } $name = "加藤"; if ($name ne "伊藤"){ print "$name は伊藤ではありません\n"; } $num = 10; if ($num > 5){ print "$num は5よりも大きい\n"; } $name = "abc"; if ($name gt "ABC"){ print "$name はABCより大きい\n"; }上記を「test2-1.pl」の名前で保存してから次のように実行して下さい。
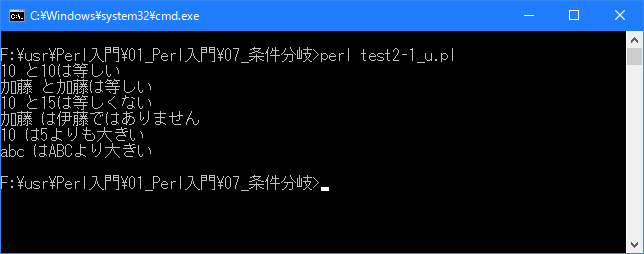
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd If]$ perl test2-1_u.pl | nkf -w 10 と10は等しい 加藤 と加藤は等しい 10 と15は等しくない 加藤 は伊藤ではありません 10 は5よりも大きい abc はABCより大きい [xxxxxxxx@dddddddddd If]$
- 論理演算子
[ 目次 ]
関係演算子を使えば簡単な条件判断は可能ですが、論理演算子を使うことで「a と bが等しい」且つ「c は dよりも大きい」などの複数の条件式を組み合わせたより複雑な条件式を記述することができます。
まずは論理演算子の種類を確認します。
演算子 名前 記述例 意味 && 論理積 AND a && b aとbが共に真の場合に真 || 論理和 OR a || b aかbの少なくとも1つが真の場合に真 ! 否定 NOT !a aが真の時に偽、偽の時に真
論理積の場合は左辺及び右辺がどちらも真となる場合に全体として真を返します。論理和の場合は左辺又は右辺の少なくともどちらか1つが真の場合に全体として真を返します。否定は右辺が真なら偽を、偽なら真を返します。
このように論理演算子は真か偽かだけを見ていますので、左辺又は右辺には関係演算子を使った条件式などを記述し、組み合わせて使用することになります。
論理積
論理積(AND)は演算子の左辺及び右辺の条件式が共に真の場合のみ全体の評価が真となります。
左辺 右辺 全体 真 真 真 真 偽 偽 偽 真 偽 偽 偽 偽
例えば次のように使用します。
my $old; $old = 24; if ($old >= 20 && $old < 30){ print "20代です\n"; }左辺の条件式である変数「$old」に格納されている値が「20」以上かどうかを評価します。結果は真(true)です。次に右辺の条件式である変数「$old」に格納されている値が「30」より小さいかどうかを評価します。結果は真(true)です。最後に&&演算子の左辺と右辺を評価し、どちらも真(true)ですので全体の条件式も真(true)となります。(なぜ&&が最後に評価されるのかは演算子の優先順位が低いためです)。
論理積の場合はまず左辺の値をみます。左辺が真の場合のみ今度は右辺の値を確認します。もし左辺が偽の場合は右側の値を確認しません。なぜならば論理積の場合は左辺及び右辺の両方が真の場合のみ真となりますので左辺が偽であった場合は右辺を確認する必要がないためです。
この左側が偽なら右側は確認しないという特性を利用したプログラムが記述されることがあります。よく使われるような記述方法はまた別のページで確認します。
論理和
論理和(OR)は演算子の右辺か左辺のどちらかの条件式が真の場合に全体の評価が真となります。
左辺 右辺 全体 真 真 真 真 偽 真 偽 真 真 偽 偽 偽
例えば次のように使用します。
my ($kokugo, $sansu); $kokugo = 58; $sansu = 75; if ($kokugo >= 60 || $sansu >= 60){ print "合格です\n"; }左辺の条件式である変数「$kokugo」に格納されている値が「60」以上かどうかを評価します。結果は偽(false)です。次に右辺の条件式である変数「$sansu」に格納されている値が「60」以上かどうかを評価します。結果は真(true)です。最後に||演算子の左辺と右辺を評価し、少なくともどちらか1つが真(true)ですので全体の条件式も真(true)となります。
論理和の場合はまず左辺の値をみます。左辺が真の場合には右辺の値を確認しません。左辺が偽の場合だけ右側の値を確認します。なぜならば論理和の場合は左辺及び右辺の少なくともどちらかが真の場合は真となりますので左辺が真であった場合は右辺を確認する必要がないためです。
論理積の場合と同じく論理和の場合に左側が真なら右側は確認しないという特性を利用したプログラムが記述されることがあります。よく使われるような記述方法はまた別のページで確認します。
否定
否定(NOT)は演算子の右辺の条件式が真の場合に全体の評価が真となり、右辺の条件式が偽の場合に全体の評価が偽となります。
右辺 全体 真 偽 偽 真
例えば次のように使用します。
my $seibetu; $seibetu = "男性"; if (!($seibetu eq "女性")){ print "女性ではありません\n"; }右辺の条件式である変数「$goukaku」が真か偽かを評価します。結果は偽(false)ですのでその否定となるため真(true)となります。
否定を使う場合には演算子の優先順位に注意して下さい。「&&」や「||」は優先順位が比較的低いので次のように記述しても意図した通りの動作をします。
my ($kokugo, $sansu); $kokugo = 58; $sansu = 75; if ($kokugo >= 60 || $sansu >= 60){ print "合格です\n"; }それに対して「!」は優先順位が「==」や「<」よりも高いので次のように記述すると先に否定が行われます。
my $seibetu; $seibetu = "男性"; if (!$seibetu eq "女性"){ print "女性ではありません\n"; }この場合は先に「!」が評価され、その後で「==」が評価されてしまいます。その為、否定を使う場合は次のように括弧()を使って優先順位を変更する必要があります。
my $seibetu; $seibetu = "男性"; if (!($seibetu eq "女性")){ print "女性ではありません\n"; }では簡単なプログラムで確認して見ます。
test3-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 論理演算子 use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my $old; $old = 24; if ($old >= 20 && $old < 30){ print "20代です\n"; } my ($kokugo, $sansu); $kokugo = 58; $sansu = 75; if ($kokugo >= 60 || $sansu >= 60){ print "合格です\n"; } my $seibetu; $seibetu = "男性"; if (!($seibetu eq "女性")){ print "女性ではありません\n"; }上記を「test3-1.pl」の名前で保存してから次のように実行して下さい。
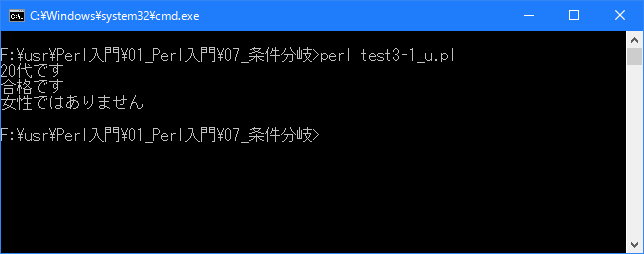
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd If]$ perl test3-1_u.pl | nkf -w 20代です 合格です 女性ではありません [xxxxxxxx@dddddddddd If]$
- 条件式が偽の時の処理(if... else)
[ 目次 ]
「if」文は記述した条件式が真(true)の時にだけ行われる処理を記述するものでした。もう一度書式を確認しておくと次のようなものでした。
if (条件式){ 条件式が真の時に実行する処理1; 条件式が真の時に実行する処理2; }「if」文には条件式が真(true)の時に実行する処理の他に条件式が偽(false)の時(真でなかった時)に実行する処理を別途指定することが出来ます。これには「if .. else」文を使用します。書式は次の通りです。
if (条件式){ 条件式が真の時に実行する処理1; 条件式が真の時に実行する処理2; }else{ 条件式が偽の時に実行する処理1; 条件式が偽の時に実行する処理2; }条件式を評価し、真(true)だった場合にはすぐ次に記述された「{」から「}」までのブロック内の処理を実行し、偽(false)だった場合にはelseの後に記述された「{」から「}」までのブロック内の処理を実行します。
例えば変数に格納された値が正の数か負の数かで処理を分ける場合には次のように記述します。
my $num; $num = 5; if ($num >= 0){ print "正の数です"; }else{ print "負の数です"; }では簡単なプログラムで確認して見ます。
test4-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 条件式が偽の時の処理(if... else) use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my $old; $old = 18; if ($old >= 20){ print "ご利用頂けます\n"; }else{ print "未成年の方はご利用頂けません\n"; } $old = 34; if ($old >= 20){ print "ご利用頂けます\n"; }else{ print "未成年の方はご利用頂けません\n"; }上記を「test4-1.pl」の名前で保存してから次のように実行して下さい。
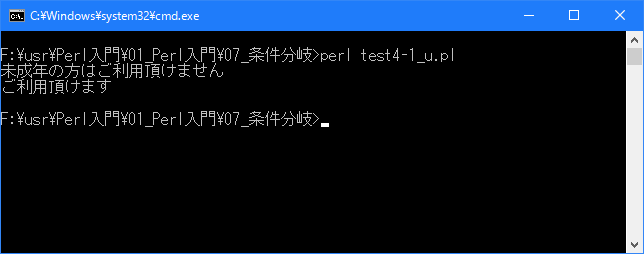
今回のサンプルでは年齢を格納する変数「$old」の値に応じて処理を分けています。
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd If]$ perl test4-1_u.pl | nkf -w 未成年の方はご利用頂けません ご利用頂けます [xxxxxxxx@dddddddddd If]$
- 複数の条件分岐(if .. elsif .. else)
[ 目次 ]
「if」文では単独の条件分岐だけではなく複数の条件分岐を使って処理を分けることが出来ます。これには「if .. elsif .. else」文を使用します。書式は次の通りです。
if (条件式1) { 条件式1が真の時に実行する処理; }elsif (条件式2) { 条件式1が偽で条件式2が真の時に実行する処理; }elsif (条件式3) { 条件式1及び条件式2が偽で条件式3が真の時に実行する処理; }else{ 全ての条件式が偽の時に実行する処理; }最初の条件式は今までの「if」文と同じです。条件式が真の場合には次に記述されたブロック内の処理を行いそしてif文を終了します。そして条件式が偽の場合だけ次の「elsif」へ進み、記述された条件式を評価します。評価した結果が真であればその次に記述されたブロック内の処理を行いif文を終了します、偽であった場合は次の「elsif」へ進みます。上から順に評価されていくことに注意して下さい。
「elsif」は必要な数だけ記述することが出来ます。また全ての条件式が偽だった場合に実行する処理として「else」の次のブロック内に処理を記述できます。「else」の部分は必要無ければ記述しなくても構いません。
※else if ではなく elsif ですので注意して下さい
例えば変数に格納された値が正の数か負の数か又は0かで処理を分ける場合には次のように記述します。
my $num; $num = 5; if ($num > 0){ print "正の数です"; }elsif ($num < 0){ print "負の数です"; }elsif ($num == 0){ print "0です"; }else{ print "その他の値です"; }では簡単なプログラムで確認して見ます。
test5-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 複数の条件分岐(if .. elsif .. else) use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my $num; $num = 12; print "数値 = $num\n"; if ($num >= 20){ print "20以上です\n"; }elsif ($num >= 10){ print "10以上20未満です\n"; }else{ print "10以下です\n"; }上記を「test5-1.pl」の名前で保存してから次のように実行して下さい。
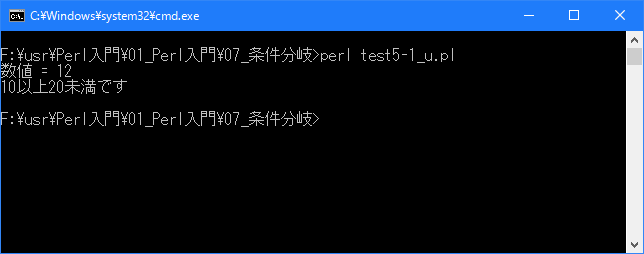
今回のサンプルでは数値を格納する変数「$num」の値に対して複数の条件式を順に評価してます。
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd If]$ perl test5-1_u.pl | nkf -w 数値 = 12 10以上20未満です [xxxxxxxx@dddddddddd If]$
- unless文
[ 目次 ]
「if」文では続いて記述された条件式が真の場合の処理を記述するのに使われますが、似た制御構造を持つものとして「unless」文があります。「unless」文は条件式が偽の場合の処理を記述するのに使われます。書式は次の通りです。
unless (条件式){ 条件式が偽の時に実行する処理1; 条件式が偽の時に実行する処理2; }条件式を評価し、条件式が偽だった場合に続くブロック内の処理を実行します。
実際のプログラム例としては次のようになります。
my $seiseki; $seiseki = 75; unless ($seiseki < 60){ print "合格です\n"; print "おめでとう\n"; }今回の例では条件式として変数「$seiseki」に格納されている値が60よりも小さいどうかを設定しています。条件式が偽となるとき、つまり変数の値が60以上の場合に「{」から「}」で囲まれたブロック内の「print "合格です\n";」が実行され、次に「print "おめでとう\n";」が実行されます。
「unless」文は「if」文を使って記述することが出来ます。先ほどの例を「if」文で書き直すと次のようになります。
my $seiseki; $seiseki = 75; if ($seiseki < 60){ }else{ print "合格です\n"; print "おめでとう\n"; }「if」文で「else」節しかないものと考えることが出来ます。又は論理否定(!)を使って次のように記述することも出来ます。
my $seiseki; $seiseki = 75; if (!($seiseki < 60)){ print "合格です\n"; print "おめでとう\n"; }どのような記述方法をしても結果は同じです。「if」文と「unless」文を混在させて使用しても構いませんが、「if」文だけを使い、条件式が真(true)の時にブロック内が実行されるように統一しておいたほうが分かりやすいのではないかと思います。
unless...else
「if」文と同じく「unless」文にも「else」を使うことが出来ます。
unless (条件式){ 条件式が偽の時に実行する処理1; 条件式が偽の時に実行する処理2; }else{ 条件式が真の時に実行する処理1; 条件式が真の時に実行する処理2; }ただこれは「if」文を使って次のように記述することが出来ます。
if (条件式){ 条件式が真の時に実行する処理1; 条件式が真の時に実行する処理2; }else{ 条件式が偽の時に実行する処理1; 条件式が偽の時に実行する処理2; }その為、あえて「unless...else」を使う必要はありません。
では簡単なプログラムで確認して見ます。
test6-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# unless文 use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my $seiseki; $seiseki = 75; unless ($seiseki < 60){ print "合格です\n"; print "おめでとう\n"; } print "お疲れ様\n";上記を「test6-1.pl」の名前で保存してから次のように実行して下さい。
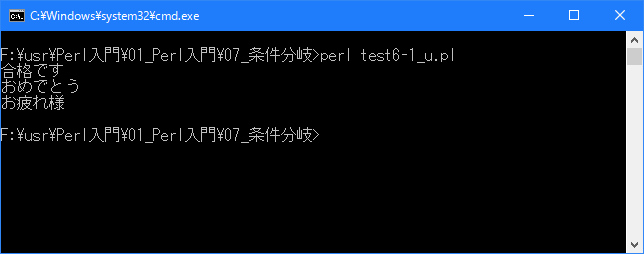
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd If]$ perl test6-1_u.pl | nkf -w 合格です おめでとう お疲れ様 [xxxxxxxx@dddddddddd If]$
- 三項演算子
[ 目次 ]
三項演算子は「if...else」を簡略化したような演算子です。まず書式を確認して下さい。
条件式 ? 真の時の値 : 偽の時の値;
三項演算子では条件式を評価し、真(true)だった場合には真の時の値を、偽(false)だった場合には偽の時の値を返します。
実際のプログラム例としては次のようになります。
my ($seiseki, $kekka); $seiseki = 75; $kekka = $seiseki > 60 ? "合格" : "不合格"; print $kekka;
今回の例では条件式である「$seiseki > 60」を評価し、真だった場合には「合格」を、偽だった場合には「不合格」を返します。結果的に今回は「合格」と言う値が変数「$kekka」に格納されます。
三項演算子は、このように条件によって値を選択したい場合に簡略化して記述できる演算子です。三項演算子はif文を使って記述することもできます。
my ($seiseki, $kekka); $seiseki = 75; if ($seiseki > 60){ $kekka = "合格"; }else{ $kekka = "不合格"; } print $kekka;三項演算子は慣れない間はいっけん分かりにくいのですが、if文を使って記述するよりも簡潔に記述できる場合も多いので慣れてくれば便利な演算子です。
では簡単なプログラムで確認して見ます。
test7-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 三項演算子 use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my ($seiseki, $kekka); $seiseki = 75; $kekka = $seiseki > 60 ? "合格" : "不合格"; print $kekka; print "\n";
上記を「test7-1.pl」の名前で保存してから次のように実行して下さい。
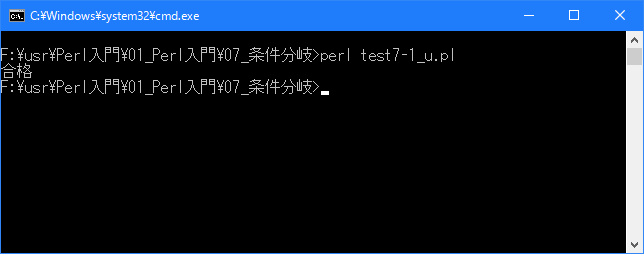
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd If]$ perl test7-1_u.pl | nkf -w 合格 [xxxxxxxx@dddddddddd If]$
- 式修飾子(if修飾子)
[ 目次 ]
if文を使って条件にあった時だけ処理を行うことが出来ますが、1つの処理だけを実行させる場合にはif文の代わりにif修飾子を使用することが出来ます。少々分かりにくいので具体的な例で考えていきます。例えば変数「$count」から1を減算する処理を行うとします。
$count = $count - 1;
この処理を$countに格納されている値が1以上の場合だけにしてみます。if文を使えば次のように記述できます。
if ($count >= 1){ $count = $count - 1; }このような文は次のようにif修飾子を使って記述することが可能です。
$count = $count - 1 if $count >= 1;
if修飾子は処理に対して実行するかどうかの条件を指定します。if修飾子の書式は次のようになります。
真の時に実行する処理 if 条件式;
if修飾子が記述されている場合は、まず条件式を評価し真(true)だった場合には式を実行します。
if修飾子はif文を使っても記述できますが、1つの処理だけを行う場合には便利な記述方法です。また逆にif修飾子では条件式が真の時に実行できる処理は1つだけです。
式修飾子はif修飾子だけではなくunless修飾子が使用できます。また繰り返し処理用としてはwhile修飾子やforeach修飾子などもあります。こちらは「繰り返し処理」で確認します。
では簡単なプログラムで確認して見ます。
test8-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 式修飾子(if修飾子) use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my $count; $count = 5; print "$count\n"; $count = $count - 10 if $count > 0; print "$count\n"; $count = $count - 10 if $count > 0; print "$count\n";
上記を「test8-1.pl」の名前で保存してから次のように実行して下さい。
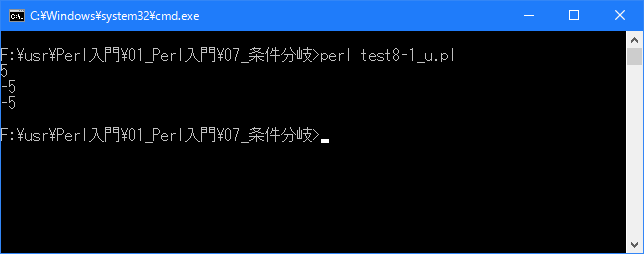
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd If]$ perl test8-1_u.pl | nkf -w 5 -5 -5 [xxxxxxxx@dddddddddd If]$
- リリースノート
[ 目次 ]- 2020/10/25 Ver=1.01 JDK_15 で確認
- 2017/03/02 Ver=1.01 初版リリース
- 関連ページ
[ 目次 ]