|
| Perlプログラム作成の文字列と数値 |
H.Kamifuji . |
- はじめに
Perlを使えば画面に何かメッセージを表示したり、計算を行うことが出来ます。この時に使用される文字列と数値について確認していきます。
当ページでは、Linux CentOS7 の Gnome で動作テストしています。
- 目 次
- 文字列
[ 目次 ]
文字列はプログラムから何かメッセージを表示する場合に使用されます。文字列は複数の文字を組み合わせたものであり、アルファベットや数 字の他に日本語も使用することが出来ます。
Perlでで文字列を表現する場合にはダブルクオーテーション(")又はシングルクオーテーション(')で囲んで表現します。
"文字列" '文字列'
具体的には次のようになります。
"abc" 'Watch' "漢字"
文字列は複数の文字から成り立っています。文字の集まりとして文字列を定義するには最初の文字から最後の文字までをダブルクオーテーション又はシングルクオーテーションで囲うことで、その間にある文字をまとめて文字列として扱います。
文字列は複数の文字から成り立っています。文字の集まりとして文字列を定義するには最初の文字から最後の文字までをダブルクオーテーション又はシングルクオーテーションで囲うことで、その間にある文字をまとめて文字列として扱います。
では文字列を画面に表示させるような簡単なサンプルを考えてみましょう。文字列を画面に表示するには次のように記述を行います。
print 文字列;
「print」の後にスペースを1つ空け、その後に画面に表示した文字列を記述します。
例えば"abc"という文字列を出力するには次のように記述します。
print "abc";
またシングルクオーテーションを使って次のように記述することも出来ます。
print 'abc';
では簡単なプログラムで確認して見ます。
サンプルプログラム
下記のサンプルを実行してみよう。
# 文字列 use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; print "Hello"; print 'こんにちは'; print "\n";
上記を「test1-1.pl」の名前で保存してから次のように実行して下さい。
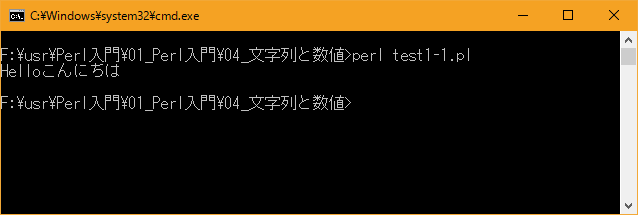
文字列が画面に表示されます。改行を行っていませんので、2つの文字列が続けて出力されています。
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Num]$ perl test1-1_u.pl | nkf -w Helloこんにちは [xxxxxxxx@dddddddddd Num]$
- 文字列の連結
[ 目次 ]
文字列と文字列を連結することができます。連結する場合は文字列と文字列をドット(.)で結びます。
"文字列1"."文字列2"
上記の場合は次のような文字列を記述した場合と同じです。
"文字列1文字列2"
固定の文字列と文字列を連結するだけであればこのような記述方法は必要ありません。変数に格納された文字列を連結させるような使い方を行います。詳しくは変数の箇所で解説します。
では簡単なプログラムで確認して見ます。
サンプルプログラム
下記のサンプルを実行してみよう。
# 文字列の連結 use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; print "こんにちは。"."お元気ですか。\n";
上記を「test2-1.pl」の名前で保存してから次のように実行して下さい。
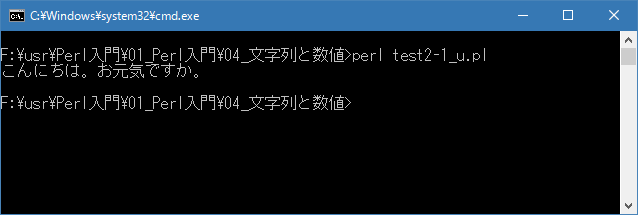
2つの文字列が連結されて画面に表示されます。
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Num]$ perl test2-1_u.pl | nkf -w こんにちは。お元気ですか。 [xxxxxxxx@dddddddddd Num]$
- 数値
[ 目次 ]
数値は整数や浮動小数点数など普段使用している数値と同じものです。数値は計算などを行うことができます。
Perlでで数値を表現する場合にはそのまま記述します。
352 27.346
数値は大きく分けると整数のものと小数点を含む実数に分けることができます。実数は浮動小数点数と呼びます。よく使われる言葉ですので覚えておいて下さい。
整数を表す場合、10進数だけではなく2進数、8進数、16進数を使用することが出来ます。10進数であればそのまま記述しますが8進数の場合は先頭に「0」を付けて記述し、16進数の場合は先頭に「0x」を付けて記述し、2進数の場合は先頭に「0b」を付けて記述します。
25 045 0x3E 0b11111111
浮動小数点数を表すには固定小数点形式を使った記述方法の他に指数表現も行えます。
1.35 3E-8
※3E-8とは3掛け10の-8乗です。
では簡単なプログラムで確認して見ます。
サンプルプログラム
下記のサンプルを実行してみよう。
# 数値 use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; print 10; print "\n"; print 0x3E; print "\n"; print 012; print "\n"; print 0b11111111; print "\n"; print 18.725; print "\n"; print 3E-8; print "\n";
上記を「test3-1_u.pl」の名前で保存してから次のように実行して下さい。
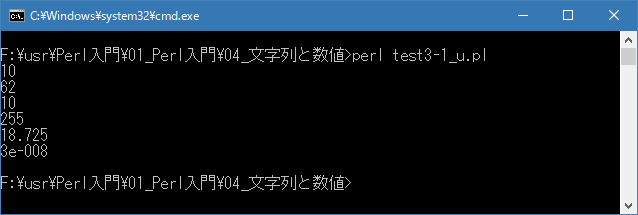
実際に実行して頂くと分かりますが、整数に関しては8進数や16進数で表現したとしても10進数の数値として扱われます。8進数や16進数として画面に出力したい場合には「sprintf」などの関数を使います。詳しくはまた別の箇所で解説します。
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Num]$ perl test3-1_u.pl | nkf -w 10 62 10 255 18.725 3e-08 [xxxxxxxx@dddddddddd Num]$
計算結果を表示
数値が文字と大きく異なる点として計算を行うことができます。四則演算は別のページで詳しく見ていきますが、ここでは簡単な例と結果だけを見てください。
下記のサンプルでは数値をそのまま表示する代わりに「10 + 4」の足し算の結果と「8 * 7」の掛け算の結果を表示しています。
サンプルプログラム
下記のサンプルを実行してみよう。
# 数値 use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; print 10 + 4; print "\n"; print 8 * 7; print "\n";
上記を「test3-2_u.pl」の名前で保存してから次のように実行して下さい。

今回のサンプルでは「10 + 4」の結果である「14」と「8 * 7」の結果である「56」が表示されています。
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Num]$ perl test3-2_u.pl | nkf -w 14 56 [xxxxxxxx@dddddddddd Num]$
- 特殊文字(エスケープシーケンス)
[ 目次 ]
文字や数値の使い方を簡単に見てきましたが、テキストとして入力を行えない特殊な文字があります。簡単な例で言えば改行です。テキストエディタ上でEnterキーを押してもテキストが改行されるだけで改行を表す文字としては入力ができません。
このような特殊な文字を入力するために「\」記号+1文字などを使い別の単語として記述することができます。このような特殊な記述の仕方をエスケープシーケンスと言います。
よく利用されるものでは次のようなものがあります。
\a 警報音 \b バックスペース \n 改行 \r 復帰 \f 改ページ \t 水平タブ \e ESC \\ 文字としての\ \$ 文字としての$ \@ 文字としての@ \; 文字としての; \' シングルクォーテーション(') \" ダブルクォーテーション(") \ooo 8進数 \xhh 16進数 \cX コントロール文字(\cCならCtrl+C) \l文字 文字を小文字 \u文字 文字を大文字 \L...\E ...を小文字 \U...\E ...を大文字 \Q...\E ...の中のメタ文字をエスケープエスケープシーケンスは文字列を構成する1つの文字として文字列の中に他の文字と組み合わせて記述することができます。代表的なものとしては改行の「\n」があります。文字列を定義する時に改行したい位置に「\n」を記述することで改行を行わせることができます。
"こんにちは\nおはようございます"
上記を出力すると次のように表示されます。
こんにちは おはようございます
なおエスケープシーケンスが特別な解釈をされるのは文字列がダブルクオーテーションで囲まれている場合です。例えばシングルクオーテーションで文字列を囲った場合に、エスケープシーケンスが記述されていても一部の例外を除いてそのままの文字として解釈されます。
'こんにちは\nおはようございます'
上記を出力すると次のように表示されます。
こんにちは\nおはようございます
今回の場合は文字列中に含まれる「\n」は改行という意味ではなく「\」と「n」と言う文字がただ並んだものとして解釈されます。
シングルクオーテーションで囲まれた文字列の中でエスケープシーケンスとして意味を持つものは「\'」と「\\」だけです。
では簡単なプログラムで確認して見ます。
サンプルプログラム
下記のサンプルを実行してみよう。
# 特殊文字(エスケープシーケンス) use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; print "こんにちは\nおはようございます\n"; print 'こんにちは\nおはようございます\n';
上記を「test4-1.pl」の名前で保存してから次のように実行して下さい。

同じ文字列を出力していますが、最初の文字列はダブルクオーテーションで囲まれているため文字列中の「\n」が改行として解釈されて出力されています。次の文字列ではシングルクオーテーションで囲まれているため文字列中の「\n」はそのままの文字として出力されています。
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Num]$ perl test4-1_u.pl | nkf -w こんにちは おはようございます こんにちは\nおはようございます\n [xxxxxxxx@dddddddddd Num]$
「\」や「"」を表示する
エスケープシーケンスではキーボードから入力しにくい文字を別の単語として表す利用方法の他に、キーボードから入力はできるけれども他の理由で表示できない文字を表す場合にも使われます。
まず「\」そのものを文字として表示したい場合です。文字列の中に「\」と「n」が続けて記述された場合を考えて下さい。
"abcd\nefg"
文字として「\」を表示したいにも関わらず「\n」が改行を表すエスケープシーケンスとして扱われてしまうためこの文字列は次のように解釈されます。
abcd efg
そこで「\」をエスケープシーケンスの特殊な文字としてではなく単なる文字として扱いたい場合には「\\」と記述します。
"abcd\\nefg"
今回の場合は「\\」が「\」と言う文字として扱われますので次のように解釈されます。
abcd\nefg
同じように「"」文字を文字列の中で使用しようとすると、文字列の終端を表す「"」と区別するために「\"」のように記述することで文字として「"」を扱うことができます。
では簡単なプログラムで確認して見ます。
サンプルプログラム
下記のサンプルを実行してみよう。
# 特殊文字(エスケープシーケンス) use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; print "abc\ndef\n"; print "abc\\ndef\n"; print "aaa\"bbb\n";
上記を「test4-2.pl」の名前で保存してから次のように実行して下さい。

エスケープシーケンスとして特別な意味を持つ「\」や、文字列を定義する時に使用される「"」も表示することができます。
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Num]$ perl test4-2_u.pl | nkf -w abc def abc\ndef aaa"bbb [xxxxxxxx@dddddddddd Num]$
- 論理値(ブール値)
[ 目次 ]
文字列や数値の他に特殊な値として論理値又はブール値と呼ばれるものがあります。論理値は個別の値を持っているわけではありません。数値又は文字列の値を2つのグループに分けたようなものと考えて下さい。
文字列や数値を論理値として区分した場合、真(true)または偽(false)のどちらかとして区分されます。文字列や数値がどちらに区分されるのかは次の規則に従います。
数値は 0 だけが偽(false) 0 以外は全て真(true)
数値の場合には0だけが偽(false)となり、0以外は真(true)となります。
文字列は空文字('')だけが偽(false) 空文字以外は全て真(true) ただし文字の'0'は数値の0と同じなので結果的に文字の'0'は偽(false)文字列の場合は空文字('')又は「'0'」の場合が偽(false)となり、それ以外は真(true)となります。文字列はシングルクオーテーションで囲った場合でもダブルクオーテーションで囲った場合でも同じです。
論理値は条件分岐の条件式などで使用されます。詳しくは条件分岐の箇所で解説しますが、条件式が真(true)なら個の処理を行い、条件式が偽(false)ならこちらの処理を行うといった使い方となります。
undef
Perlでは未定義値を表す「undef」と言う値が用意されています。「undef」も偽(false)となります。
具体的な使用法は条件分岐の箇所でご説明します。
- リリースノート
[ 目次 ]- 2020/10/25 Ver=1.01 JDK_15 で確認
- 2017/02/28 Ver=1.01 初版リリース
- 関連ページ
[ 目次 ]