|
| Perlプログラム作成の値の書式指定 |
H.Kamifuji . |
- はじめに
値を指定の書式で整形し、文字列として取得する方法を確認します。例えば数値を16進数や8進数にしたり桁数を指定して0詰めで表示したりすることが出来ます。
当ページでは、Linux CentOS7 の Gnome で動作テストしています。
- 目 次
- printf関数とsprintf関数
[ 目次 ]
文字列を指定のフォーマットで出力するには「printf」関数又は「sprintf」関数を使います。まずはこの関数の簡単な使い方を確認しておきます。
書式は次の通りです。
printf([ファイルハンドル] 書式指定文字列, リスト); 戻り値 = sprintf(書式指定文字列, リスト);
「printf」関数は指定のファイルハンドルに対して整形した結果の文字列を出力します。ファイルハンドルを省略した場合は標準出力であるSTDOUTに対して出力しますので結果的に画面に出力されます。「sprintf」関数は整形した結果を文字列として返します。
どちらの関数もリストに指定した値を、書式指定文字列に指定した方法で整形します。結果を画面に出力するなら「printf」関数を使い、いったん変数に保存したいのであれば「sprintf」関数を使って下さい。
書式指定文字列にはリストに記述された値を変換する方法などを記述します。複数の値を指定し、それぞれの値に対応する変換方法を1つの書式指定文字列の中で記述することが出来ます。
実際の記述方法は次のようになります。
printf("番号は %03d です", 24);上記を実際に実行すると「番号は 024 です」が表示されます。変換元の値である「24」を書式指定文字列の中に記述された「%03d」によって変換し、全体を画面に表示しています。
なんとなく使い方がお分かり頂けましたでしょうか。詳細は次のページから確認していきます。
では簡単なプログラムで確認して見ます。
test1-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# printf関数とsprintf関数 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; printf("番号は %03d です\n", 24);上記を「test1-1.pl」の名前で保存してから次のように実行して下さい。
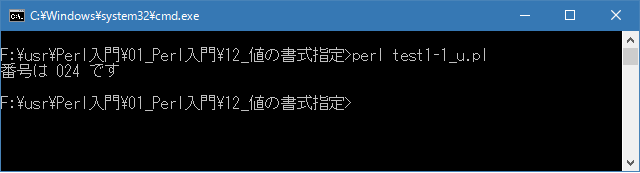
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Format]$ perl test1-1_u.pl | nkf -w 番号は 024 です [xxxxxxxx@dddddddddd Format]$
- 書式指定文字列の記述
[ 目次 ]
ここからは書式指定文字列の記述方法を確認します。書式指定文字列は、そのまま表示される文字列と、値を変換して表示するフォーマット指定子を組み合わせて記述します。
フォーマット指定子は値の変換方法を具体的に記述する部分で、変換される値の数だけフォーマット指定子を記述する必要があります。フォーマット指定子の書式は次の通りです。
%[フラグ][最小幅][.精度/最大幅]型指定子
フォーマット指定子は「%」で始まり「型指定子」を記述します。またオプションとして指定可能な項目として「フラグ」「最小幅」「精度/最大幅」があります。
詳細な使い方は次のページ以降で細かく確認していきます。ここでは例として「%03d」と言うフォーマット指定子使ってみます。「%03d」を指定した場合は対応する値を「10進数の数値で幅を3桁にし0詰めにする」ものです。
printf("%03d", 30);上記の場合は書式指定文字列にフォーマット指定子だけを記述しています。この場合は「30」と言う値を「%03d」を使って変換された「030」と言う文字列が画面に出力されます。
フォーマット指定子以外の文字列
書式指定文字列にはフォーマット指定子を記述しますが、フォーマット指定子以外の文字列を記述することも可能です。書式指定文字列の中のフォーマット指定子以外の文字列は、そのまま文字列として使われます。
printf("数値は %03d です", 30);上記の場合は書式も指定文字列の中に「数値は 」と「 です」と言う文字列が記述されています。フォーマット指定子以外の文字列はそのまま文字列として使われますので結果として「数値は 030 です」と言う文字列が表示されます。
複数の値を変換
また変換する値は複数指定することができます。複数の値を変換する場合は、指定した値の数だけフォーマット指定子を記述します。
printf("Aは %03d 円、Bは %03d 円です", 30, 80);上記の場合は変換する値が2つですのでフォーマット指定子も2つ記述しています。結果として「Aは 030円、Bは 080円です」と画面に表示されます。
値を複数指定する場合は、このようにカンマ(,)で区切って並べて記述して下さい。
1番目に記述された値は、書式指定文字列の中に最初に現れたフォーマット指定子を使って変換されます。同じように2番目の値は2番目に現れたフォーマット指定子で変換されていきます。このように記述された順番に従って変換が行われます。
では簡単なプログラムで確認して見ます。
test2-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 書式指定文字列の記述 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; printf("Aは %03d 円、Bは %03d 円です\n", 30, 80);上記を「test2-1.pl」の名前で保存してから次のように実行して下さい。
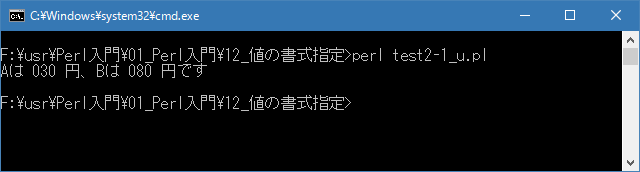
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Format]$ perl test2-1_u.pl | nkf -w Aは 030 円、Bは 080 円です [xxxxxxxx@dddddddddd Format]$
- 型指定子
[ 目次 ]
フォーマット指定子の中で必須のものが型指定子です。型指定子は整形する値のデータ型を指定します。例えば整数として扱うのか浮動小数点数で扱うのかなどの指定です。型指定子は次のようなものがあります。
%d 10進数 %u 符号無し10進数 %o 符号無し8進数 %x 符号無し16進数 %e 指数形式の浮動小数点 %f 固定小数点形式の浮動小数点 %g 浮動小数点(%e 又は %f のどちらかの形式) %X %xと同じだがアルファベットを大文字で表示 %E %eと同じだが大文字のEを使用 %G %gと同じだが大文字のEを使用 %b 符号無し2進数
型指定子を変更することで同じ値であっても異なるデータ型の値にすることが出来ます。例えば次のような使い方となります。
printf("%d\n", 30); printf("%x\n", 30); printf("%o\n", 30);例えば数値の「30」に対して型指定子を10進数を表す「%d」を使うとそのまま「10」と言う文字列として表示されます。代わりに16進数を表す「%x」を使って書式を指定すれば「1e」と言う文字列として表示されます。8進数を表す「%o」を使って書式を指定すれば「36」と言う文字列として表示されます。
数値のデータ型以外の型指定子
数値に対するデータ型を決めるための型指定子の他に次のような型指定子が用意されています。
%% パーセントの文字そのもの %c 文字コードに対応した文字 %s 文字列 %p 値のポインタ %n 文字数を次の変数に格納
「%%」は「%」と言う文字を書式文字列の中で使用する場合に使います。これは「%」と言う文字が特殊な用途で使われているためであり、エスケープシーケンスと同じ扱いです。その為、対応する値は必要ありません。
「%c」は指定した値に文字コードに対応する文字となります。例えば「65」に対して型指定子「%c」を使うと対応する「A」と言う文字となります。
「%s」は指定した値に文字列をそのまま文字列として表示します。動的に文字列を指定したい場合に使います。
「%p」は指定した値に対するポインタを表示します。使い道は良く分かっていません。
「%n」は出力された文字数を対応する値の箇所に指定した変数に格納します。その為「%n」自体は何も出力しません。
my $count; printf("num = %d%n\n", 45, $count); print "$count\n";上記の場合、「%n」の前に「num = 45」と言う文字列が出力されています。文字列の文字数は「8」文字であるため、「%n」に対応する値の箇所に指定された「$count」に数値の「8」が格納されます。
なお日本語を記述した場合はバイト数で数えるようです。使用している文字コードにもよりますがUTF-8で記述しいる場合は日本語1文字に付き3バイトとなります。
my $count; printf("数値は%d%n\n", 45, $count); print "$count\n";上記の場合は「数値は45」と言う文字列が出力されています。バイト数にすると「11」となるため変数「$count」には「11」が格納されます。
では簡単なプログラムで確認して見ます。
test3-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 型指定子 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; printf("%d\n", 30); printf("%x\n", 30); printf("%o\n", 30); printf("%c\n", 65); printf("%c\n", 66); printf("%e\n", 0.00123); printf("%f\n", 0.00123); printf("%s=%d%%\n", "確率", 90); my $count; printf("数値は%d%n\n", 45, $count); print "バイト数は$count\n";上記を「test3-1.pl」の名前で保存してから次のように実行して下さい。
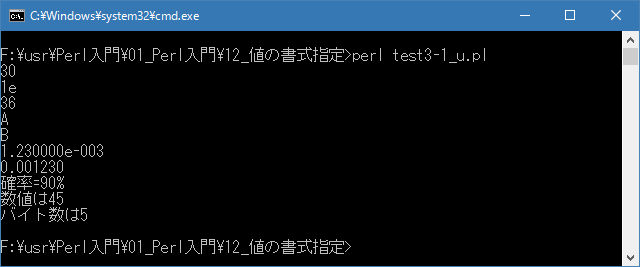
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Format]$ perl test3-1_u.pl | nkf -w 30 1e 36 A B 1.230000e-03 0.001230 確率=90% 数値は45 バイト数は5 [xxxxxxxx@dddddddddd Format]$
- フラグ
[ 目次 ]
フォーマット指定子のオプションの1つであるフラグについて確認します。
%[フラグ][最小幅][.精度/最大幅]型指定子
フラグは次のものが用意されています。
space 数値が正だった場合に空白を先頭に付けます + 数値が正だった場合に「+」を先頭に付けます - 左詰めに設定(デフォルトは右詰め) 0 右詰めの場合に0詰めを行う # 8進数の場合に「0」、16進数の場合に「0x」又は「0X」、2進数の場合 に「0b」を先頭に付けます。(全て数値が0以外の場合のみ)。それでは1つ1つ確認していきます。
フラグにスペースを指定
フラグにスペースを記述した場合、正の数値の前に1文字空白を付けます。使い方は次の通りです。
printf("[%d]\n", 30); printf("[% d]\n", 30); printf("[% d]\n", -30);上記の場合、結果は次のように表示されます。
[30] [ 30] [-30]
フラグに「+」を指定
フラグに「+」を記述した場合、正の数値の前に「+」を付けます。使い方は次の通りです。
printf("[%4d]\n", 30); printf("[%-4d]\n", 30);右詰めにした場合は最小幅が指定されていなければ必要な桁数のみ表示されるため左詰めとの違いが分かりません。その為、上記では最小幅を「4」に設定しています。(最小幅については別のページで詳しく確認します)。
上記の場合、結果は次のように表示されます。
[ 30] [30 ]
フラグに「0」を指定
フラグに「0」を記述した場合、0詰めで表示されます(右詰めの場合のみ)。使い方は次の通りです。
printf("[%4d]\n", 30); printf("[%04d]\n", 30);最小幅が指定されていなければ必要な桁数のみ表示されるため0詰めは行われません。その為、上記では最小幅を「4」に設定しています。(最小幅については別のページで詳しく確認します)。
上記の場合、結果は次のように表示されます。
[ 30] [0030]
フラグに「#」を指定
フラグに「#」を記述した場合、8進数の場合に「0」、16進数の場合に「0x」又は「0X」、2進数の場合に「0b」を先頭に付けます。ただし数値が0の場合は付きません。使い方は次の通りです。
printf("[%#o]\n", 30); printf("[%#x]\n", 30); printf("[%#b]\n", 30);上記の場合、結果は次のように表示されます。
[036] [0x1e] [0b11110]
では簡単なプログラムで確認して見ます。
test4-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# フラグ # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; printf("[%d]\n", 30); printf("[% d]\n", 30); printf("[% d]\n", -30); printf("[%d]\n", 30); printf("[%+d]\n", 30); printf("[%+d]\n", -30); printf("[%4d]\n", 30); printf("[%-4d]\n", 30); printf("[%4d]\n", 30); printf("[%04d]\n", 30); printf("[%#o]\n", 30); printf("[%#x]\n", 30); printf("[%#b]\n", 30);上記を「test4-1.pl」の名前で保存してから次のように実行して下さい。
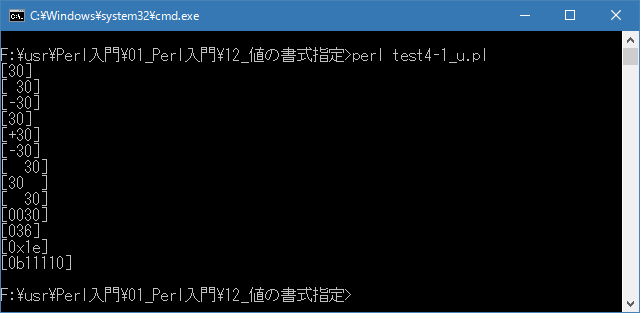
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Format]$ perl test4-1_u.pl | nkf -w [30] [ 30] [-30] [30] [+30] [-30] [ 30] [30 ] [ 30] [0030] [036] [0x1e] [0b11110] [xxxxxxxx@dddddddddd Format]$
- 最小幅
[ 目次 ]
フォーマット指定子のオプションの1つである最小幅について確認します。
%[フラグ][最小幅][.精度/最大幅]型指定子
結果として取得できる文字列の最小の幅を指定します。結果が最小幅よりも少ない場合は空白や0詰めなどで埋められます。また、結果が最小幅よりも大きい場合には最小幅の設定に関わらず必要な幅となります。
使い方は次のようになります。
printf("[%5d]\n", 30); printf("[%#5o]\n", 30);型変換子との組み合わせの他に、フラグと最小幅を同時に設定することも可能です。
なおフラグによって正の数の前に「+」を付けたり、16進数の前に「0x」を付けた場合などは、これらのフラグによって付加された文字も含めた結果に対して最小幅の設定が行われます。
では簡単なプログラムで確認して見ます。
test5-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 最小幅 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; printf("[%d]\n", 30); printf("[%5d]\n", 30); printf("[%5d]\n", -30); printf("[%-5d]\n", -30); printf("[%#o]\n", 30); printf("[%#5o]\n", 30); printf("[%#x]\n", 30); printf("[%#5x]\n", 30); printf("[%#b]\n", 2); printf("[%#5b]\n", 2); printf("[%15e]\n", 12.3); printf("[%15f]\n", 12.3); printf("[%3d]\n", 760128);上記を「test5-1.pl」の名前で保存してから次のように実行して下さい。
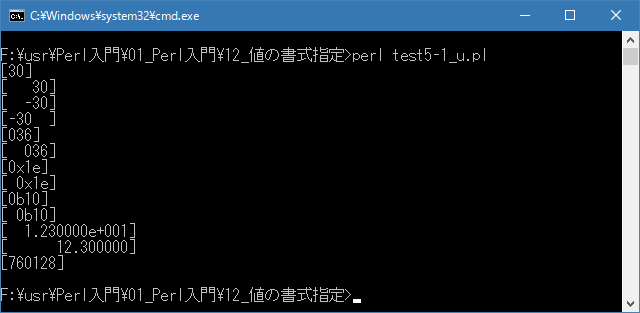
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Format]$ perl test5-1_u.pl | nkf -w [30] [ 30] [ -30] [-30 ] [036] [ 036] [0x1e] [ 0x1e] [0b10] [ 0b10] [ 1.230000e+01] [ 12.300000] [760128] [xxxxxxxx@dddddddddd Format]$
- 精度/最大幅
[ 目次 ]
フォーマット指定子のオプションの1つである精度/最大幅について確認します。
%[フラグ][最小幅][.精度/最大幅]型指定子
このオプション項目は、数値に対して設定した場合は精度となり、文字列に対して設定した場合は最大幅となります。
浮動小数点数に対して設定
浮動小数点数に対して精度を指定した場合は、小数点以下の桁数となります。
まず固定小数点形式の浮動小数点に対して試してみます。
printf("%f\n", 0.012); printf("%.0f\n", 0.012); printf("%.1f\n", 0.012); printf("%.2f\n", 0.012); printf("%.3f\n", 0.012); printf("%.4f\n", 0.012);上記では型変換子として「%f」を指定し、さらに精度を0から4までの数値で順に指定しています。結果は次のようになります。
0.012000 0 0.0 0.01 0.012
指定した精度によって結果の小数点以下の桁数が変化することが確認できます。では今度は指数形式の浮動小数点で試してみます。
printf("%e\n", 0.012); printf("%.0e\n", 0.012); printf("%.1e\n", 0.012); printf("%.2e\n", 0.012); printf("%.3e\n", 0.012);上記では型変換子として「%e」を指定し、さらに精度を0から4までの数値で順に指定しています。結果は次のようになります。
1.200000e-002 1e-002 1.2e-002 1.20e-002 1.200e-002
指定した精度によって結果の小数点以下の桁数が変化することが確認できます。
整数に対して設定
整数に対して精度を指定した場合は、数値部分の桁数となります。数値部分が精度に指定した桁よりも少ない場合は0詰めとなります。数値部分が精度よりも多い場合は何も変更は加えられません。
printf("[%.2d]\n", 123); printf("[%.4d]\n", 123); printf("[%.6d]\n", 123);上記では型変換子として「%d」を指定し、さらに精度を変化させて指定しています。結果は次のようになります。
[123] [0123] [000123]
数値部分が精度で指定した値よりも少ない場合は変化ありませんが、精度で指定した値の方が大きい場合は0詰めで表示されます。
printf("[%8.2d]\n", 123); printf("[%8.4d]\n", 123); printf("[%8.6d]\n", 123);今度は最小幅と合わせて指定した場合です。結果は次のようになります。
[ 123] [ 0123] [ 000123]
次は16進数の数値に対して設定してみます。
printf("[%.6x]\n", 123); printf("[%#.6x]\n", 123);上記では型変換子として「%x」を指定し、さらに精度を設定しています。結果は次のようになります。
[00007b] [0x00007b]
1つはフラグとして「#」を合わせて指定しています。結果として数値の先頭に「0x」が付きますが、精度として指定した桁数はあくまで数値部分に対して有効となります。
文字列に対して設定
文字列に対しては精度ではなく最大幅として機能します。設定した最大幅よりも文字列が長い場合は最大幅で切り捨てられます。
printf("[%s]\n", "Javascript"); printf("[%.5s]\n", "Javascript"); printf("[%.15s]\n", "Javascript");上記では型変換子として「%s」を指定し、さらに精度を設定しています。結果は次のようになります。
[Javascript] [Javas] [Javascript]
最大幅が文字数よりも少ない場合は文字列が最大幅で切り捨てられます。最大幅が文字数よりも多い場合は何も変更は加えられません。
では簡単なプログラムで確認して見ます。
test6-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 精度/最大幅 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; printf("%f\n", 0.012); printf("%.4f\n", 0.012); printf("%e\n", 0.012); printf("%.3e\n", 0.012); printf("[%.4d]\n", 123); printf("[%.6d]\n", 123); printf("[%8.6d]\n", 123); printf("[%.6x]\n", 123); printf("[%#.6x]\n", 123); printf("[%s]\n", "Javascript"); printf("[%.5s]\n", "Javascript");上記を「test6-1.pl」の名前で保存してから次のように実行して下さい。
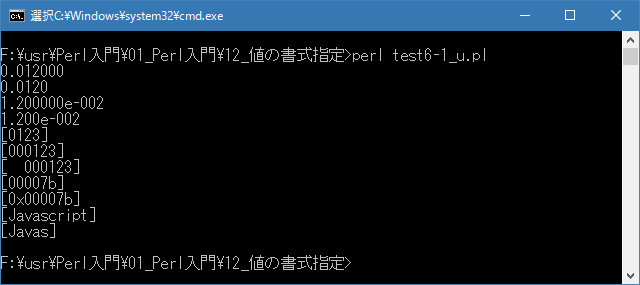
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Format]$ perl test6-1_u.pl | nkf -w 0.012000 0.0120 1.200000e-02 1.200e-02 [0123] [000123] [ 000123] [00007b] [0x00007b] [Javascript] [Javas] [xxxxxxxx@dddddddddd Format]$
- 精度/最大幅の桁数を値で指定
[ 目次 ]
フォーマット指定子のオプションの1つである精度/最大幅を指定する時に、直接数値を指定する代わりに「*」を記述すると、桁数を値として指定することが出来ます。
例として精度を6桁に設定する場合は次のように記述していました。
printf("[%.6d]\n", 123);精度の部分を値で指定するには、精度を指定する位置に「*」を記述し、変換する値を指定する前に精度の桁数を指定します。
printf("[%.*d]\n", 6, 123);この2つは同じ結果となり次のように表示されます。
[000123]
この書式を使用する場合には1つの書式指定文字列に対して桁数と変換する値の2つの値を指定することになります。
では簡単なプログラムで確認して見ます。
test7-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 精度/最大幅の桁数を値で指定 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; printf("[%.6d]\n", 123); printf("[%.*d]\n", 6, 123); printf("[%s] [%.*s] \n", "Hello", 3, "Hello");上記を「test7-1.pl」の名前で保存してから次のように実行して下さい。
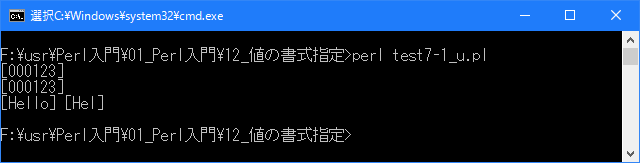
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Format]$ perl test7-1_u.pl | nkf -w [000123] [000123] [Hello] [Hel] [xxxxxxxx@dddddddddd Format]$
- 値をインデックス指定で使用
[ 目次 ]
特に指定しない場合は、リストとして並べられた値は順番に変換されていきます。
ここでは値が並べられた順ではなく、値のインデックスを指定することで、任意の位置の値を使用する方法を確認します。少し分かりにくいですが次の例を見て下さい。
printf("A=%d, B=%d\n", 123, 456);上記の場合は「A=123, B=456」と表示されます。リストとして値が2つ指定されていますが、並べられた順に値が変換されていくためです。では次のように変更してみます。
printf("A=%2\$d, B=%1\$d\n", 123, 456);今度の場合は「A=456, B=123」と表示されます。これは変換される値を並べられた順ではなくどの値を使用するかをインデックスを使って指定しています。
インデックスは値が並べられた順に1,2,3,...となっています。0からではないので注意して下さい。そしてフォーマット指定子の中で次のように指定します。
インデックス$
記述する位置はフォーマット指定子の中の「%」の直後です。例えば2番目の値を使用する場合は「2$」となります。
注意する点として、書式指定文字列を指定する時にシングルクオーテーションを使用している場合はこのまま記述できますが、ダブルクオーテーションを使用している場合は「$」に対してエスケープシーケンスする必要があります。よってこの場合は「2\$」のように記述します。
printf("A=%2\$d, B=%1\$d\n", 123, 456); printf('A=%2$d, B=%1$d', 123, 456);同じ書式指定文字列の中で同じ値を繰り返し指定しても構いませんし、インデックスを指定せずにフォーマット指定子を記述する方法と併用しても構いません。
printf("A=%2\$d, B=%2\$d\n", 123, 456); printf("%2\$d, %d, %1\$d, %d\n", 123, 456);上記を実行すると次のように表示されます。
A=456, B=456 456, 123, 123, 456
インデックスを指定しないフォーマット指定子については、通常通りリストに指定された値が先頭から順に使用されます。
では簡単なプログラムで確認して見ます。
test8-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 値をインデックス指定で使用 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; printf("A=%d, B=%d\n", 123, 456); printf("A=%2\$d, B=%1\$d\n", 123, 456); printf("A=%2\$d, B=%2\$d\n", 123, 456); printf("%2\$d, %d, %1\$d, %d\n", 123, 456);上記を「test8-1.pl」の名前で保存してから次のように実行して下さい。
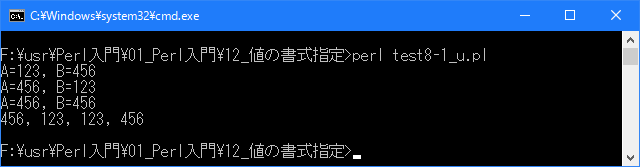
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxxx@ddddddddd Format]$ perl test8-1_u.pl | nkf -w A=123, B=456 A=456, B=123 A=456, B=456 456, 123, 123, 456 [xxxxxxxxx@ddddddddd Format]$
- リリースノート
[ 目次 ]- 2020/10/25 Ver=1.01 JDK_15 で確認
- 2017/03/04 Ver=1.01 初版リリース
- 関連ページ
[ 目次 ]