|
| Perlプログラム作成のファイル操作 |
H.Kamifuji . |
- はじめに
Perlからファイルを読み込んだり書き出したりする方法を確認します。
当ページでは、Linux CentOS7 の Gnome で動作テストしています。
- 目 次
- ファイルハンドル
[ 目次 ]
Perlのプログラムでファイルに対して何らかの操作を行う場合、指定したファイルとPerlのプログラムの間でやり取りを行うための通信経路(コネクション)を用意する必要があります。ファイルに対して何かを書き込んだりファイルから読み込んだりする場合はこのコネクションを経由して行われます。
プログラムでは必要になった時にファイルとのコネクションを開いて通信経路を用意し、ファイルに対する操作が終わったらコネクションを閉じます。別のファイルに対して何らかのやり取りが必要にならば、別のコネクションを開いて使用します。
複数のファイルとのやり取りを行う場合には複数のコネクションを使用します。コネクションを区別するためにコネクションに対して付ける名前をファイルハンドルと呼びます。書き込みや読み込みを行う場合はファイルハンドルを指定することで、どのファイルに対して操作を行うのかを指示することが出来ます。
ファイルハンドル名の付け方
ファイルハンドル名は次の規則に従っていれば任意の名前を設定することができます。
変数名にはアルファベット・数字・アンダーバー("_")を使うことが出来ます (例) name, old20, _hokan 先頭の文字に数字は利用できません (例) 10kago は不可 大文字と小文字は区別します。 (例) old と Old は別の変数名となりますこれは変数名を付ける時の規則と同じです(ただし「$」や「%」などの接頭語のようなものはありません)。小文字でも大文字でも規則上は問題ありませんが、慣習としてファイルハンドルは全て大文字で名前を付けることになっているようです。例えば次のようになります。
DATAFILE LOG
標準で用意されているファイルハンドル
プログラムの中で任意のファイルとの間で使用するファイルハンドルとは別に、標準で用意されているファイルハンドルがあります。
STDIN 標準入力。キーボードからの入力など。 STDOUT 標準出力。画面への出力など。 STDERR 標準エラー。エラーとしての出力。
これらのファイルハンドルは標準で用意されており、コネクションは開かれた状態です。その為、特に何もしなくてもファイルハンドルを指定してコネクションを利用することが出来ます。
ファイルハンドル「STDIN」は標準入力と呼ばれるものでファイルの代わりにキーボードやパイプ/リダイレクトなどからデータを読み込む場合に使用されます。
ファイルハンドル「STDOUT」は標準出力と呼ばれるものでファイルの代わりに画面やパイプ/リダイレクトなどに対してデータを出力する場合に使用されます。
ファイルハンドル「STDERR」は標準エラーと呼ばれるもので標準出力と同じく画面やパイプ/リダイレクトなどに対してデータを出力する場合に使用されます。標準出力との違いは、エラーが発生した時に使用されるという点です。
このようにキーボードからの入力や画面への出力などもファイルと同じようにコネクションを開き、対応するファイルハンドルに対して操作を行うことでファイルに対する読み書きと同じように処理することが出来ます。
- ファイルのオープンとクローズ
[ 目次 ]
それではファイルから何らかの情報を読み込んだり書き込んだりするために、ファイルを開く方法を確認します。ファイルを開くためには「open」関数を使用します。
よく使われる書式は次の通りです。
open(ファイルハンドル名, "ファイル名"); open(ファイルハンドル名, "モード", "ファイル名");
対象のファイル名を指定し、ファイルとの間で開くコネクションに付ける名前をファイルハンドルとして指定します。モードについては後のページで詳しく解説します。
例えば次のように記述します。
open(DATAFILE, "data.txt");
上記の場合では、プログラムが実行されているディレクトリと同じディレクトリ上にある「data.txt」に対して読み込み専用でコネクションを開き、コネクションに対して「DATAFILE」と言うファイルハンドルを設定します。
「open」関数はファイルを開くことに成功すると真(true)を返し、失敗すると未定義値(undef)を返します。(「open」関数について詳しくは「open関数」を参照して下さい)。
ファイルを閉じる
ファイルを開くとファイルに対する様々な操作が行えます。ファイルの中身を読み込んだり書き込んだりを行った後でファイルに対する操作が必要無くなった時点でファイルを閉じるようにします。
ファイルを閉じるためには「close」関数を使います。書式は次の通りです。
close(ファイルハンドル名);
例えば次のように記述します。
open(DATAFILE, "data.txt"); close(DATAFILE);
引数には開いているコネクションに対して付けられたファイルハンドル名を指定します。「close」関数はファイルを閉じることに成功すると真(true)を返し、失敗すると偽(false)を返します。(「close」関数について詳しくは「close関数」を参照して下さい)。
では簡単なプログラムで確認して見ます。
test2-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# ファイルのオープンとクローズ # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; if (open(DATAFILE, "data.txt")){ print "data.txtを開く事に成功しました\n"; if (close(DATAFILE)){ print "data.txtを閉じる事に成功しました\n"; }else{ print "data.txtを閉じる事に失敗しました\n"; } }else{ print "data.txtを開く事に失敗しました\n"; } if (open(DATAFILE, "data1.txt")){ print "data1.txtを開く事に成功しました\n"; if (close(DATAFILE)){ print "data1.txtを閉じる事に成功しました\n"; }else{ print "data1.txtを閉じる事に失敗しました\n"; } }else{ print "data1.txtを開く事に失敗しました\n"; }上記を「test2-1.pl」の名前で保存してから次のように実行して下さい。

今回はプログラムと同じディレクトリに「data.txt」と言うテキストファイルを用意してあります。(中身はなんでも構いません)。その為、「data.txt」ファイルを開く事は成功しますが「data1.txt」ファイルは存在しないのでファイルを開くことに失敗しています。
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd File]$ perl test2-1_u.pl | nkf -w data.txtを開く事に成功しました data.txtを閉じる事に成功しました data1.txtを開く事に失敗しました [xxxxxxxx@dddddddddd File]$
- ファイルオープン時のエラー処理
[ 目次 ]
「open」関数を使ってファイルを開こうとして失敗した場合、プログラムの実行を中断するには「die」関数を使ってプログラムを終了させる方法がよく使われます。(「die」関数については「die関数」を参照して下さい)。
「open」関数は失敗すると未定義値(undef)を返しますので次のように「if」文を使って記述することが出来ます。
if (!open(DATAFILE, "data.txt")){ die("error :$!"); }又は「unless」文を使って次のように記述することも出来ます。
unless (open(DATAFILE, "data.txt")){ die("error :$!"); }この記述方法でも問題はありませんが、Perlでは「or」演算子を使って次のように記述する場合が多いです。
open(DATAFILE, "data.txt") or die("error :$!");「or」演算子は左辺の式をまず評価します。左辺が真の場合は右辺は評価せずに次の行へ進みますが、左辺が偽の場合は右辺を評価します。その為、上記の式は左辺に記述された「open」関数をまず実行し結果を評価します。「open」関数が成功すればそのまま次の行へ進みますが、「open」関数が失敗し「undef」を返してきた場合には「undef」は偽(false)として扱われますので右辺を実行します。結果的に「open」関数が失敗した場合にだけ「die」関数が実行されることになります。
どの記述方法でも同じなのですが、簡潔に記述でき分かりやすい(if修飾子を使うと先に「die」関数が来てしまう)ので「or」演算子を使った記述がよく使用されているようです。
では簡単なプログラムで確認して見ます。
test3-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# ファイルオープン時のエラー処理 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; open(DATAFILE, "data.txt") or die("error :$!"); print "data.txtを開く事に成功しました\n"; close(DATAFILE); open(DATAFILE, "data1.txt") or die("error :$!"); print "data1.txtを開く事に成功しました\n"; close(DATAFILE);上記を「test3-1.pl」の名前で保存してから次のように実行して下さい。
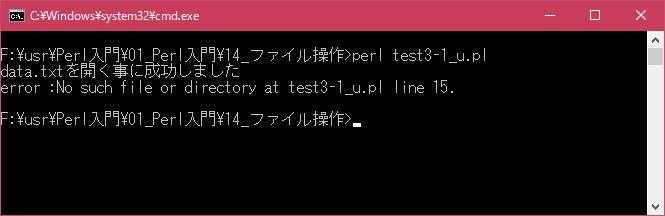
今回はプログラムと同じディレクトリに「data.txt」と言うテキストファイルを用意してあります。その為、「data.txt」ファイルを開く事は成功しますが「data1.txt」ファイルは存在しないのでファイルを開くことに失敗しエラーを表示してプログラムを終了しています。
Linux 環境では、':encoding(cp932)' を指定するとエラーメッセージ表示時に固まります。デフォルト文字コード(UTF-8)で実行するように下記のように変更しました。
# ファイルオープン時のエラー処理 # use strict; use warnings; # use utf8; # デフォルト文字コードを利用 # binmode STDIN, ':encoding(cp932)'; # binmode STDOUT, ':encoding(cp932)'; # binmode STDERR, ':encoding(cp932)'; open(DATAFILE, "data.txt") or die("error :$!"); print "data.txtを開く事に成功しました\n"; close(DATAFILE); open(DATAFILE, "data1.txt") or die("error :$!"); print "data1.txtを開く事に成功しました\n"; close(DATAFILE);Linux 環境での実行結果は、下記です。
[xxxxxxxx@dddddddddd File]$ perl test3-1_u.pl data.txtを開く事に成功しました error :そのようなファイルやディレクトリはありません at test3-1_u.pl line 15. [xxxxxxxx@dddddddddd File]$
- テキストデータを読み込む
[ 目次 ]
ファイルを開いた後でファイルからデータを読み込む方法を確認します。
標準入力からデータを繰り返し読み込むには次のように記述していました。(詳しくは「while/for文を使い標準入力から繰り返し値を取得」を参照して下さい)。
while (my $line =
ここで「STDIN」は標準入力を表すファイルハンドルでした。この標準入力に対するファイルハンドルを、任意のファイルを開く際に指定したファイルハンドルに変更することでファイルからデータを読み込むことが出来ます。){ chomp($line); print "$line\n"; }
例えば次のように記述します。
open(DATAFILE, "< data.txt")) or die("error :$!"); while (my $line = <DATAFILE>){ chomp($line); print "$line\n"; }先ほどのサンプルと異なる点は、データを読み込みたいファイルを開きファイルハンドルを割り当て、そしてそのファイルハンドルからデータを読み出している点だけです。(なお「open」関数のファイル名の前に「< 」が付いています。これはファイルを読み込み専用で開く場合に記述する記号です。詳しくは後のページで解説します)。
ファイルからデータを読み込む場合は、ファイルの終端を読み込むと「<ファイルハンドル>」が未定義値(undef)を返します。その為、ファイルの終端まで読み込んだ時点でwhile文は終了となります。
文字コードの指定
ファイルの読み書きを行う場合には、対象のファイルの文字コードを指定する必要があります。詳しくは「文字コードの指定」で解説しますが、例えば「UTF-8」に設定されたファイルから読み書きを行う場合には、プログラムの中で次のように記述して下さい。
use open ":utf8";
では簡単なプログラムで確認して見ます。
test4-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
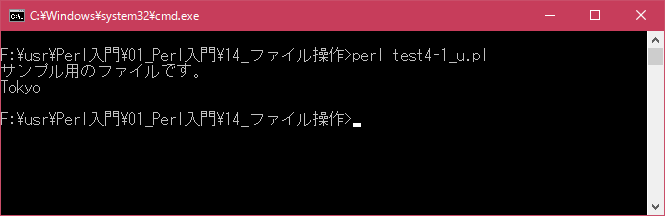
# テキストデータを読み込む # use strict; use warnings; use utf8; use open ":utf8"; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; open(DATAFILE, "< data4-1_u.txt") or die("Error:$!"); while(my $line = <DATAFILE>){ chomp($line); print "$line\n"; }上記を「test4-1.pl」の名前で保存してから次のように実行して下さい。
今回はカレントディレクトリに「data4-1.txt」と言うファイルを用意します。
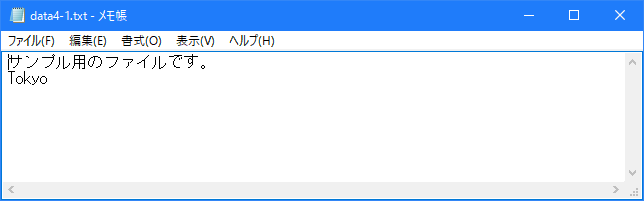
コマンドプロンプトを起動し、プログラムを保存したディレクトリに移動してから次のように実行して下さい。
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd File]$ perl test4-1_u.pl | nkf -w サンプル用のファイルです。 Tokyo [xxxxxxxx@dddddddddd File]$
- テキストデータを書き込む
[ 目次 ]
今度はファイルへデータを書き込む方法を確認します。
今までのサンプルでも画面に文字列などを出力する場合には「print」関数を使用していました。
print "書き出したいデータ";
「print」関数は実際には次のような構文となっています。
print ファイルハンドル リスト;
指定されたファイルハンドルに対して、指定されたリストの内容を書き出します。ファイルハンドルは省略可能であり、省略された場合は標準出力である「STDOUT」が指定されたものと見なされます。よって今までは本来次のように記述する代わりに「STDOUT」を省略して記述していました。
print STDOUT "書き出したいデータ";
標準出力の代わりに任意のファイルを開く際に指定したファイルハンドルに変更することで、ファイルに対して指定したデータを書き込むことが出来ます。
例えば次のように記述します。
open(DATAFILE, ">> data.txt") or die("error :$!"); print DATAFILE "書き出したいデータ";先ほどのサンプルと異なる点は、データを書き出したいファイルを開きファイルハンドルを割り当て、そしてそのファイルハンドルに対してデータを書き出している点だけです。(なお「open」関数のファイル名の前に「>> 」が付いています。これはファイルを書き込み専用(追加書き込み)で開く場合に記述する記号です。詳しくは後のページで解説します)。
この場合は既にファイルに含まれている内容を変更せずに、ファイルの最後にデータを追加します。
では簡単なプログラムで確認して見ます。
test5-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# テキストデータを書き込む # use strict; use warnings; use utf8; use open ":utf8"; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; open(DATAFILE, ">> data5-1.txt") or die("Error:$!"); print DATAFILE "大阪\n"; print DATAFILE "Osaka\n";上記を「test5-1.pl」の名前で保存してから次のように実行して下さい。
今回はカレントディレクトリに「data5-1.txt」と言うファイルを用意します。
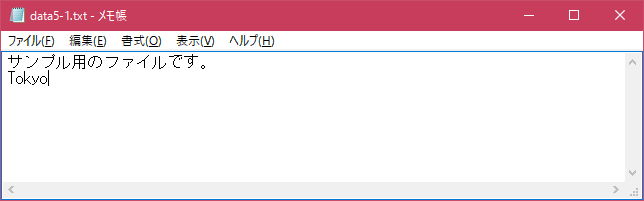
コマンドプロンプトを起動し、プログラムを保存したディレクトリに移動してから次のように実行して下さい。
今回のプログラムでは指定したファイルに2つの行を追加しています。プログラム実行後に改めて「data5-1.txt」ファイルを確認してみます。
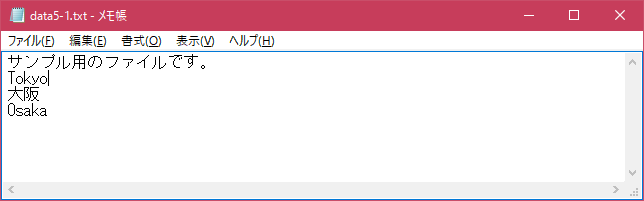
ファイルの中に2行が追加されていることが確認できます。
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd File]$ perl test5-1_u.pl | nkf -w [xxxxxxxx@dddddddddd File]$
- 「<」モード(読み込み)
[ 目次 ]
「open」関数を使ってファイルを開く際に、どのような目的で利用するのかをモードで指定することが出来ます。例えば読み込み専用でファイルを開いたり、読み書き両方の使用のためにファイルを開いたりすることが出来ます。ここからは各モードを順に試していきます。
まず最初に「<」モードを試してみます。このモードの場合は読み込み専用でファイルを開きます。書式は次のどちらかを使用します。
open(ファイルハンドル, "< ファイル名"); open(ファイルハンドル, "<", "ファイル名");
引数を2つ使う場合にはファイル名の前に「< 」を付けます。引数を3つ使う場合には2番目の引数に「<」指定し、3番目の引数にファイル名を指定します。なおモードを省略した場合にはこのモードとなります。
「<」モードの場合は次の通りです。
・読み込み専用 ・ファイルが存在していた場合、ファイルを開いた時にファイルの内容を変更しない ・ファイルが存在してなかった場合、エラー
実際には次のように記述します。
open(DATAFILE, "<", "data.txt") or die("error :$!");この場合、「data.txt」と言うファイルを読み込み専用で開きます。
では簡単なプログラムで確認して見ます。
test6-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 「<」モード(読み込み) # use strict; use warnings; use utf8; use open ":utf8"; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; open(DATAFILE, "<", "data6-1_u.txt") or die("Error:$!"); while(my $line = <DATAFILE>){ chomp($line); print "$line\n"; } close(DATAFILE);上記を「test6-1.pl」の名前で保存してから次のように実行して下さい。
今回はカレントディレクトリに「data6-1.txt」と言うファイルを用意します。
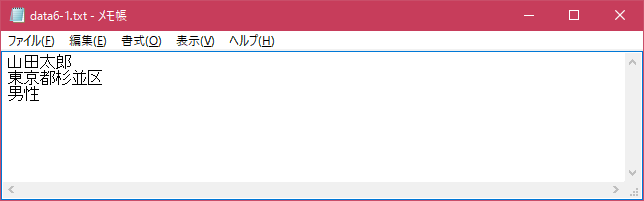
コマンドプロンプトを起動し、プログラムを保存したディレクトリに移動してから次のように実行して下さい。
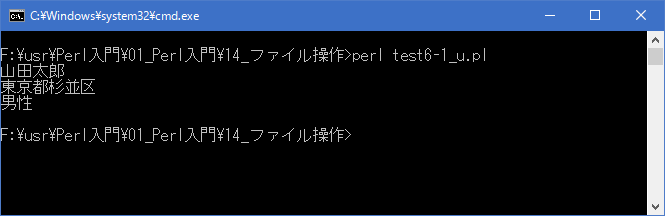
今回のサンプルではファイルの内容を読み込み画面に表示しています。
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd File]$ perl test6-1_u.pl | nkf -w 山田太郎 東京都杉並区 男性 [xxxxxxxx@dddddddddd File]$
- 「>」モード(書き込み)
[ 目次 ]
次は「>」モード(書き込み)です。このモードの場合は書き込み専用でファイルを開きます。書式は次のどちらかを使用します。
open(ファイルハンドル, "> ファイル名"); open(ファイルハンドル, ">", "ファイル名");
引数を2つ使う場合にはファイル名の前に「> 」を付けます。引数を3つ使う場合には2番目の引数に「>」指定し、3番目の引数にファイル名を指定します。
「>」モードの場合は次の通りです。
・書き込み専用 ・ファイルが存在していた場合、ファイルを開いた時にファイルサイズを0にする ・ファイルが存在してなかった場合、新規にファイルを作成
指定したファイルが存在していた場合はいったんファイルサイズを0にしてから書き込みを行いますので、上書きでの書き込みということになります。また指定したファイルが存在していなかった場合でもエラーとならず、新規にファイルが作成されます。
実際には次のように記述します。
open(DATAFILE, ">", "data.txt") or die("error :$!");この場合、「data.txt」と言うファイルを書き込み専用で開きます。
では簡単なプログラムで確認して見ます。
test7-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 「>」モード(書き込み) # use strict; use warnings; use utf8; use open ":utf8"; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; open(DATAFILE, ">", "data7-1.txt") or die("Error:$!"); print DATAFILE "加藤 花子\n"; print DATAFILE "東京都新宿区\n"; print DATAFILE "女性"; close(DATAFILE); open(DATAFILE, ">", "data7-2.txt") or die("Error:$!"); print DATAFILE "山崎 一郎\n"; print DATAFILE "大阪府吹田市\n"; print DATAFILE "男性"; close(DATAFILE);上記を「test7-1.pl」の名前で保存してから次のように実行して下さい。
今回はカレントディレクトリに「data7-1.txt」と言うファイルを用意します。
コマンドプロンプトを起動し、プログラムを保存したディレクトリに移動してから次のように実行して下さい。
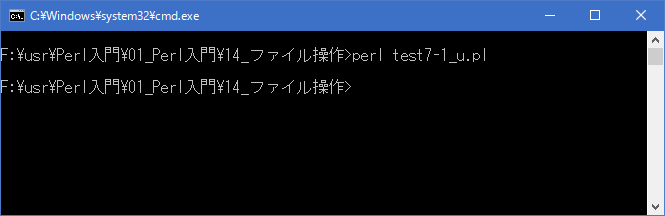
まず存在していた「data7-1.txt」ファイルを開き書き込みを行っています。ファイルが存在し、既に何かデータが含まれていた場合であっても、いったんファイルの中身をクリアし先頭から書き込みを行います。結果的に「data7-1.txt」ファイルは次のようになります。
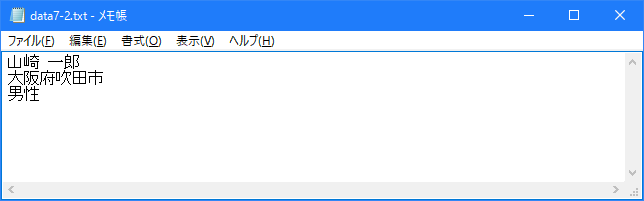
次に存在していなかった「data7-2.txt」ファイルを指定してファイルを開いています。「>」モードの場合はファイルが存在しなかった場合には新規に作成しますので、「data7-2.txt」ファイルが作成され書き込みが行われます。結果的に「data7-2.txt」ファイルは次のようになります。
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd File]$ perl test7-1_u.pl | nkf -w [xxxxxxxx@dddddddddd File]$
- 「>>」モード(書き込み)
[ 目次 ]
次は「>>」モード(書き込み)です。このモードの場合は書き込み専用でファイルを開きます。書式は次のどちらかを使用します。
open(ファイルハンドル, ">> ファイル名"); open(ファイルハンドル, ">>", "ファイル名");
引数を2つ使う場合にはファイル名の前に「>> 」を付けます。引数を3つ使う場合には2番目の引数に「>>」指定し、3番目の引数にファイル名を指定します。
「>>」モードの場合は次の通りです。
・書き込み専用 ・ファイルが存在していた場合、ファイルを開いた時にファイルの内容を変更しない ・ファイルが存在してなかった場合、新規にファイルを作成
指定したファイルが存在していた場合はファイルの内容を変更せずにファイルの最後に書き込みを行いますので、追加書き込みということになります。また指定したファイルが存在していなかった場合でもエラーとならず、新規にファイルが作成されます。
実際には次のように記述します。
open(DATAFILE, ">>", "data.txt") or die("error :$!");この場合、「data.txt」と言うファイルを書き込み専用で開きます。
では簡単なプログラムで確認して見ます。
test8-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 「>>」モード(書き込み) # use strict; use warnings; use utf8; use open ":utf8"; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; open(DATAFILE, ">>", "data8-1.txt") or die("Error:$!"); print DATAFILE "加藤 花子\n"; print DATAFILE "東京都新宿区\n"; print DATAFILE "女性"; close(DATAFILE); open(DATAFILE, ">>", "data8-2.txt") or die("Error:$!"); print DATAFILE "山崎 一郎\n"; print DATAFILE "大阪府吹田市\n"; print DATAFILE "男性"; close(DATAFILE);上記を「test8-1.pl」の名前で保存してから次のように実行して下さい。
今回はカレントディレクトリに「data8-1.txt」と言うファイルを用意します。
コマンドプロンプトを起動し、プログラムを保存したディレクトリに移動してから次のように実行して下さい。
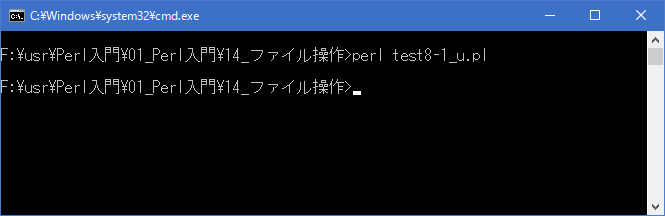
まず存在していた「data8-1.txt」ファイルを開き書き込みを行っています。ファイルの中身は変更せずにファイルの最後に追加を行います。結果的に「data8-1.txt」ファイルは次のようになります。
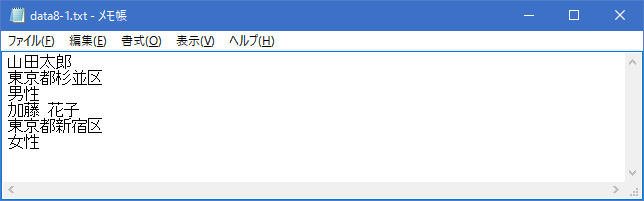
次に存在していなかった「data8-2.txt」ファイルを指定してファイルを開いています。「>>」モードの場合はファイルが存在しなかった場合には新規に作成しますので、「data8-2.txt」ファイルが作成され書き込みが行われます。結果的に「data8-2.txt」ファイルは次のようになります。
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxxx@dddddddddd File]$ perl test8-1_u.pl | nkf -w [xxxxxxxxx@dddddddddd File]$
- 「+<」モード(読み書き)
[ 目次 ]
次は「+<」モード(読み書き)です。このモードの場合は読み込みと書き込みの両方が利用できる状態でファイルを開きます。書式は次のどちらかを使用します。
open(ファイルハンドル, "+< ファイル名"); open(ファイルハンドル, "+<", "ファイル名");
引数を2つ使う場合にはファイル名の前に「+< 」を付けます。引数を3つ使う場合には2番目の引数に「+<」指定し、3番目の引数にファイル名を指定します。
「+<」モードの場合は次の通りです。
・読み込み、書き込みの両方とも可 ・ファイルが存在していた場合、ファイルを開いた時にファイルの内容を変更しない ・ファイルが存在してなかった場合、エラー ・ファイルポインタは先頭
書き込みの時には元のファイルの内容を変更しませんが、ファイルポインタは先頭になっていますので書き込みを行うと順に上書きされていきます。また指定したファイルが存在しなかった場合はエラーとなります。
実際には次のように記述します。
open(DATAFILE, "+<", "data.txt") or die("error :$!");この場合、「data.txt」と言うファイルを読み書き両用で開きます。
では簡単なプログラムで確認して見ます。
test9-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 「+<」モード(読み書き) # use strict; use warnings; use utf8; use open ":utf8"; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; open(DATAFILE, "+<", "data9-1.txt") or die("Error:$!"); print DATAFILE "加藤 花子\n"; close(DATAFILE); open(DATAFILE, "+<", "data9-1.txt") or die("Error:$!"); print "変更後:\n"; while(my $line = <DATAFILE>){ chomp($line); print "$line\n"; } close(DATAFILE); open(DATAFILE, "+<", "data9-2.txt") or die("Error:$!"); print DATAFILE "加藤 花子\n"; print DATAFILE "東京都新宿区\n"; print DATAFILE "女性"; close(DATAFILE);上記を「test9-1.pl」の名前で保存してから次のように実行して下さい。
今回はカレントディレクトリに「data9-1.txt」と言うファイルを用意します。
コマンドプロンプトを起動し、プログラムを保存したディレクトリに移動してから次のように実行して下さい。
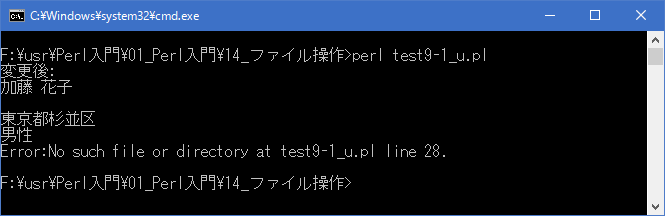
まず存在していた「data9-1.txt」ファイルを開き追加で書き込みを行っています。ファイルを開いた時点ではファイルの中身は変更されませんが、ファイルポインタが先頭にあるため書き込みを行うと先頭から順に上書きされていきます。
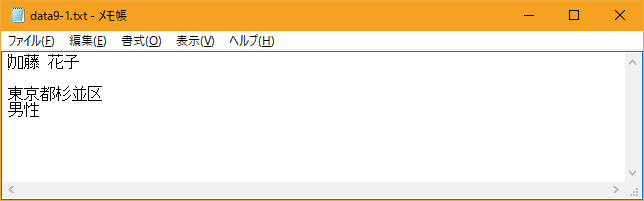
書き込みを行った後で、改めてファイルの先頭から順にデータを読み込み、画面に表示しています。
次に存在していなかった「data9-2.txt」ファイルを指定してファイルを開いていますが、ファイルが存在しなかった場合はエラーとなります。
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd File]$ perl test9-1_u.pl 変更後: 加藤 花子 東京都杉並区 男性 Error:そのようなファイルやディレクトリはありません at test9-1_u.pl line 28. [xxxxxxxx@dddddddddd File]$
ファイル data9-1.txt は、下記のように変更されています。
[xxxxxxxx@dddddddddd File]$ nkf -w data9-1.txt 加藤 花子 東京都杉並区 男性 [xxxxxxxx@dddddddddd File]$
- 「+>」モード(読み書き)
[ 目次 ]
次は「+>」モード(読み書き)です。このモードの場合は読み込みと書き込みの両方が利用できる状態でファイルを開きます。書式は次のどちらかを使用します。
open(ファイルハンドル, "+> ファイル名"); open(ファイルハンドル, "+>", "ファイル名");
引数を2つ使う場合にはファイル名の前に「+> 」を付けます。引数を3つ使う場合には2番目の引数に「+>」指定し、3番目の引数にファイル名を指定します。
「+>」モードの場合は次の通りです。
・読み込み、書き込みの両方とも可 ・ファイルが存在していた場合、ファイルを開いた時にファイルサイズを0にする ・ファイルが存在してなかった場合、新規にファイルを作成
指定したファイルが存在していた場合はいったんファイルサイズを0にしてから書き込みを行いますので、上書きでの書き込みということになります。また指定したファイルが存在していなかった場合でもエラーとならず、新規にファイルが作成されます。
実際には次のように記述します。
open(DATAFILE, "+>", "data.txt") or die("error :$!");この場合、「data.txt」と言うファイルを読み書き両用で開きます。
では簡単なプログラムで確認して見ます。
test10-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 「+>」モード(読み書き) # use strict; use warnings; use utf8; use open ":utf8"; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; open(DATAFILE, "+>", "data10-1.txt") or die("Error:$!"); print DATAFILE "加藤 花子\n"; print DATAFILE "東京都新宿区\n"; print DATAFILE "女性"; close(DATAFILE); open(DATAFILE, "<", "data10-1.txt") or die("Error:$!"); print "追加後:\n"; while(my $line = <DATAFILE>){ chomp($line); print "$line\n"; } close(DATAFILE); open(DATAFILE, "+>", "data10-2.txt") or die("Error:$!"); print DATAFILE "山崎 一郎\n"; print DATAFILE "大阪府吹田市\n"; print DATAFILE "男性"; close(DATAFILE);上記を「test10-1.pl」の名前で保存してから次のように実行して下さい。
今回はカレントディレクトリに「data10-1.txt」と言うファイルを用意します。
コマンドプロンプトを起動し、プログラムを保存したディレクトリに移動してから次のように実行して下さい。
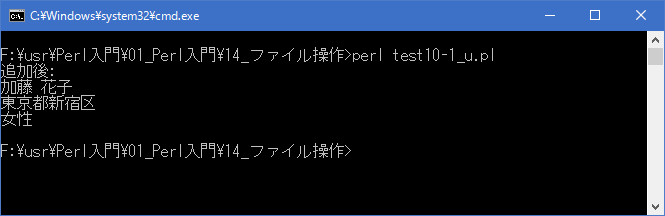
まず存在していた「data10-1.txt」ファイルを開き書き込みを行っています。ファイルが存在し、既に何かデータが含まれていた場合であっても、いったんファイルの中身をクリアし先頭から書き込みを行います。変更後の内容を確認するために、今度は「<」モードで「data10-1.txt」ファイルを開き含まれているデータを読み出して表示しています。
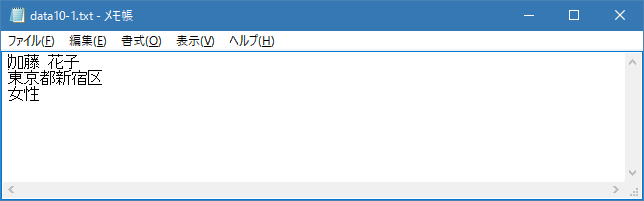
次に存在していなかった「data10-2.txt」ファイルを指定してファイルを開いています。「+>」モードの場合はファイルが存在しなかった場合には新規に作成しますので、「data10-2.txt」ファイルが作成され書き込みが行われます。結果的に「data10-2.txt」ファイルは次のようになります。

Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd File]$ perl test10-1_u.pl | nkf -w 追加後: 加藤 花子 東京都新宿区 女性 [xxxxxxxx@dddddddddd File]$
- 「+>>」モード(読み書き)
[ 目次 ]
次は「+>>」モード(読み書き)です。このモードの場合は読み込みと書き込みの両方が利用できる状態でファイルを開きます。書式は次のどちらかを使用します。
open(ファイルハンドル, "+>> ファイル名"); open(ファイルハンドル, "+>>", "ファイル名");
引数を2つ使う場合にはファイル名の前に「+>> 」を付けます。引数を3つ使う場合には2番目の引数に「+>>」指定し、3番目の引数にファイル名を指定します。
「+>>」モードの場合は次の通りです。
・読み込み、書き込みの両方とも可 ・ファイルが存在していた場合、ファイルを開いた時にファイルの内容を変更しない ・ファイルが存在してなかった場合、新規にファイルを作成 ・ファイルポインタは最後
指定したファイルが存在していた場合はファイルの内容を変更せずにファイルの最後に書き込みを行いますので、追加書き込みということになります。また指定したファイルが存在していなかった場合でもエラーとならず、新規にファイルが作成されます。
実際には次のように記述します。
open(DATAFILE, "+>>", "data.txt") or die("error :$!");この場合、「data.txt」と言うファイルを読み書き両用で開きます。
では簡単なプログラムで確認して見ます。
test11-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 「+>>」モード(読み書き) # use strict; use warnings; use utf8; use open ":utf8"; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; open(DATAFILE, "+>>", "data11-1.txt") or die("Error:$!"); print "追加前:\n"; while(my $line = <DATAFILE>){ chomp($line); print "$line\n"; } print DATAFILE "加藤 花子\n"; print DATAFILE "東京都新宿区\n"; print DATAFILE "女性"; close(DATAFILE); open(DATAFILE, "+>>", "data11-1.txt") or die("Error:$!"); print "追加後:\n"; while(my $line = <DATAFILE>){ chomp($line); print "$line\n"; } close(DATAFILE); open(DATAFILE, "+>>", "data11-2.txt") or die("Error:$!"); print DATAFILE "山崎 一郎\n"; print DATAFILE "大阪府吹田市\n"; print DATAFILE "男性"; close(DATAFILE);上記を「test11-1.pl」の名前で保存してから次のように実行して下さい。
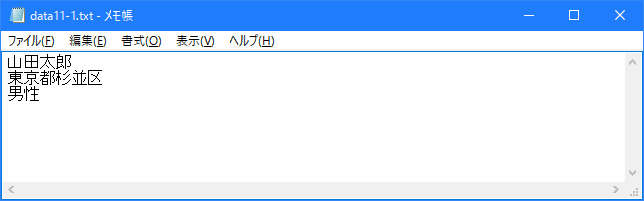
今回はカレントディレクトリに「data11-1.txt」と言うファイルを用意します。
コマンドプロンプトを起動し、プログラムを保存したディレクトリに移動してから次のように実行して下さい。
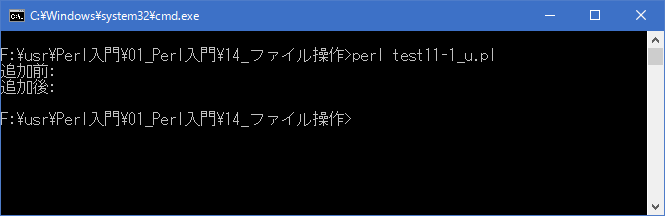
まず存在していた「data11-1.txt」ファイルを開きます。。そして内容を一度読み込んで画面に出力した後で、追加で書き込みを行っています。その後同じファイルを再度開き追加で書き込みが行われているか確認するために再度読み込みを行って画面に出力しています。
今回読み込みを行っていますが何も表示されていません。これは「+>>」モードで開いた場合、ファイルポインタが最後に置かれるためです。ファイルポインタとはファイルの中で読み込みや書き込みを行う位置のことです。ファイルポイントが最後にあるので、そこから読み込みを始めても何も読むことが出来ません。追加で書き込みを行った後に再度開いた場合も同じです。ただし、「data11-1.txt」ファイルには追加で書き込みは行われていますので実際にファイルを確認してみると次のようになっています。
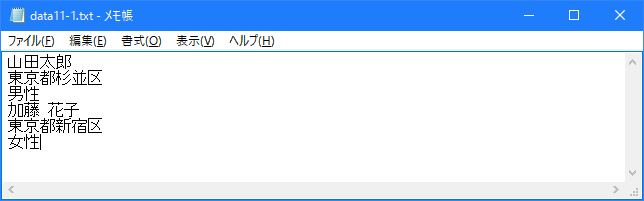
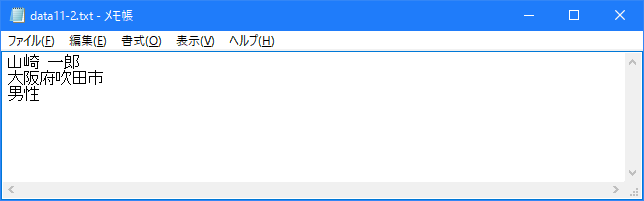
次に存在していなかった「data11-2.txt」ファイルを指定してファイルを開いています。「+>>」モードの場合はファイルが存在しなかった場合には新規に作成しますので、「data11-2.txt」ファイルが作成され書き込みが行われます。結果的に「data11-2.txt」ファイルは次のようになります。
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd File]$ perl test11-1_u.pl | nkf -w 追加前: 追加後: [xxxxxxxx@dddddddddd File]$
- 文字コードの指定
[ 目次 ]
ファイルからテキストデータを読み込む場合には、ファイルの文字コードをPerlの内部的な文字コードに変換する必要があります。またファイルへテキストデータを書き出す場合はPerlの内部的な文字コードからファイルで使用する文字コードへ変換する必要があります。
入出力に関する文字コードを設定する方法としては、全ての入出力に対してまとめて指定する方法と、「open」関数を使用する時に個別に指定する方法があります。
open プラグマ
まずは全ての入力、全ての出力、又は全ての入出力に対してまとめて文字コード指定する方法を確認します。「open」プラグマを使います。
use open IN => ":utf8"; use open OUT => ":utf8"; use open IO => ":utf8";
use open IN => ":encoding(文字コード)"; se open OUT => ":encoding(文字コード)"; use open IO => ":encoding(文字コード)";
「use open IN」は入力の文字コードを、「use open OUT」は出力の文字コードを、「use open IO」は入出力の文字コードを指定します。
文字コードの指定方法は、UTF-8の場合は「:utf8」と記述し、UTF-8以外の場合は「:encoding(文字コード)」で記述します。例えば「encoding(euc-jp)」や「encoding(cp932)」のように記述します。
use open IN => ":utf8"; use open OUT => ":encoding(cp932)";
また入出力をまとめて指定する場合は次のように記述することも可能です。
use open IO ":utf8"; use open IO ":encoding(cp932)";
入力の対象となるファイルや、出力の対象となるファイルが同じ文字コードとなっている場合はこの記述方法を使用して下さい。
open関数の引数に指定する
個々のファイルとのやり取りの時に個別に文字コードを設定する方法です。「open」関数の3つの引数を指定する書式を使います。
open(ファイルハンドル名, "モード:文字コード", "ファイル名");
モードを指定する時に合わせて文字コードを指定します。文字コードの指定方法は「open」プラグマの時と同じくUTF-8の場合は「utf8」と記述し、それ以外の場合は「encoding(文字コード)」と記述します。
例えば次のように記述します。
open(DATAFILE, "<:utf8", "datain.txt"); open(DATAFILE, ">:encoding(cp932)", "dataout.txt");
この場合、「datain.txt」を読み込みで開く時に文字コードをUTF-8に設定し、「dataout.txt」を書き込みで開く時に文字コードを「cp932」に設定します。
では簡単なプログラムで確認して見ます。
test12-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 文字コードの指定 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; open(DATAFILE, "<:utf8", "data12-1.txt") or die("Error:$!"); while(my $line = <DATAFILE>){ chomp($line); print "$line\n"; } close(DATAFILE); open(DATAFILE, ">:encoding(cp932)", "data12-2.txt") or die("Error:$!"); print DATAFILE "加藤 花子\n"; print DATAFILE "東京都新宿区\n"; print DATAFILE "女性"; close(DATAFILE);上記を「test12-1.pl」の名前で保存してから次のように実行して下さい。
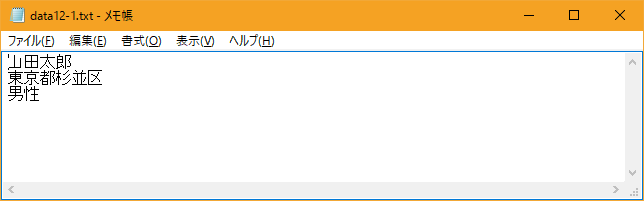
今回はカレントディレクトリに「data12-1.txt」と言うファイルを用意します。
コマンドプロンプトを起動し、プログラムを保存したディレクトリに移動してから次のように実行して下さい。
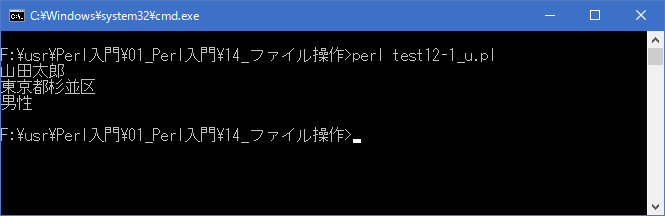
「UTF-8」で記述されたファイルの内容を読み込み画面に表示しています。
また「data12-2.txt」と言うファイル名を指定し書き込み用にファイルを開いています。「data12-2.txt」は存在していないファイルですので新規に作成されます。書き込み時の文字コードとして「cp932(Shift_JIS)」を指定していますので、作成された「data12-2.txt」ファイルの文字コードは「cp932」となっています。

Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd File]$ perl test12-1_u.pl | nkf -w 山田太郎 東京都杉並区 男性 [xxxxxxxx@dddddddddd File]$
- リリースノート
[ 目次 ]- 2020/10/25 Ver=1.01 JDK_15 で確認
- 2017/03/05 Ver=1.01 初版リリース
- 関連ページ
[ 目次 ]