|
| Perlプログラム作成のリストと配列 |
H.Kamifuji . |
- はじめに
複数の値をまとめて管理する為に使用されるのがリストと配列です。リストは順序を持って並べられた複数の値のことであり、配列とは複数の値を管理するために変数をまとめて管理する為に使用されるものです。ここではリストと配列の使い方について確認していきます。
※配列やリストに関する関数は「配列/リスト」を参照して下さい。
当ページでは、Linux CentOS7 の Gnome で動作テストしています。
- 目 次
- リストとは
[ 目次 ]
今まで使用してきた値は数値であっても文字列であっても1つの値でした。例えば変数に数値を代入する場合の例で考えてみます。
$var = 10;
上記の場合は「10」と言う1つの値を変数「$var」に格納しています。
それに対してリストというのは複数の値を表すのに使用されます。リストの書式は次の通りです。
(値1, 値2, 値3, ...)
リストでは複数の値をカンマで区切って並べ括弧()で囲います。値はいくつ並べても構いません。リストに含まれる各値は要素とも呼ばれます。
例えば数値の「1」「2」「3」と言う3つの値を持つリストは次のように表されます。
(1, 2, 3)
同じように文字列の「男性」「女性」と言う2つの値を持つリストは次のように表されます。
("男性", "女性")リストは順番を持っています。値が記述された順に並べられていると考えて下さい。上の例で言えば「男性」の次の値は「女性」であり、「女性」の前の値は「男性」です。
リストを変数に格納する
値と同じくリストを変数に格納することが出来ます。リストは複数の値を並べて記述したものですから、格納される変数も複数になります。リストを変数に格納する場合は次の書式となります。
(変数1, 変数2, 変数3, ...) = (値1, 値2, 値3, ...);
格納する変数もリストと同じようにカンマで区切って並べ括弧()で囲います。これは次のように記述した場合と同じです。
変数1 = 値1; 変数2 = 値2; 変数3 = 値3;
ただし正確には同じではありません。格納されるリストの中の値は全ての格納が終わるまで変化しません。これについては「リストの要素に変数を使用」を参照して下さい。
実際のプログラム例としては次のようになります。
my ($var1, $var2, $var3); ($var1, $var2, $var3) = ("月曜", "火曜", "水曜");では簡単なプログラムで確認して見ます。
test1-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# リストとは # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my ($var1, $var2, $var3); ($var1, $var2, $var3) = ("月曜", "火曜", "水曜"); print "$var1\n"; print "$var2\n"; print "$var3\n";上記を「test1-1.pl」の名前で保存してから次のように実行して下さい。
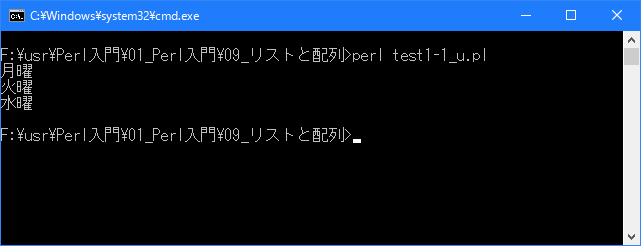
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Array]$ perl test1-1_u.pl | nkf -w 月曜 火曜 水曜 [xxxxxxxx@dddddddddd Array]$
- リストの要素に変数を使用
[ 目次 ]
リストの各要素には数値や文字列などだけではなく変数や式を記述することができます。
リストの要素に式を記述するというのは次のような場合です。
my ($str1, $str2); my $name = "伊藤"; ($str1, $str2) = ($name, "東京都");
この場合、リストの1番目の要素は変数「$name」です。要素として変数を記述した場合には、その時変数に格納されていた値があたかも値として記述されているように扱われます。よって変数「$str1」には変数「$name」に格納されている「伊藤」が格納されます。
次にリストには式を記述することが出来ます。例えば次のような場合です。
my ($num1, $num2); my $zei = 0.5; ($num1, $num2) = (20 * $zei, 800);
この場合、リストの1番目の要素は「20 * $zei」と言う処理が行われた結果となります。よって変数「$num1」には数値の「20」と変数「$zei」に格納されている「0.5」が乗算された結果だる「10」が格納されます。
リストの要素として変数を格納することができるので次のような記述も可能です。
my ($num1, $num2); $num1 = 30; $num2 = 20; ($num1, $num2) = ($num2, $num1);
この場合は変数「$num1」と変数「$num2」に格納されていた値が入れ替わって格納されます。この時注意して頂きたいのは変数「$num1」に変数「$num2」が格納された時点で変数「$num1」に格納される値は変化しますが、次に変数「$num2」に格納される変数「$num1」の値は変化する前の値が格納されます。
つまりリストを使って変数に値を格納する場合は、まずリストの値が一時保管された後でその保管された値が順に変数に格納されるのであって、変数に格納する過程では格納されるリストの値は変化しません。
では簡単なプログラムで確認して見ます。
test2-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# リストの要素に変数を使用 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my ($str1, $str2); my $name = "伊藤"; ($str1, $str2) = ($name, "東京都"); print "$str1\n"; print "$str2\n"; my ($num1, $num2); my $zei = 0.5; ($num1, $num2) = (20 * $zei, 800); print "$num1\n"; print "$num2\n"; ($num1, $num2) = ($num2, $num1); print "$num1\n"; print "$num2\n";
上記を「test2-1.pl」の名前で保存してから次のように実行して下さい。
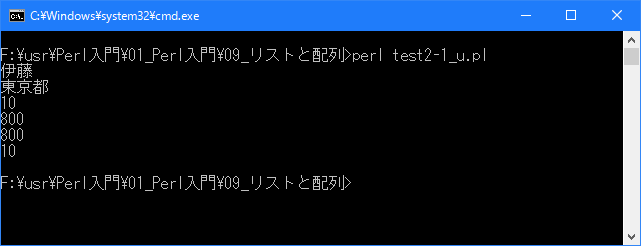
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Array]$ perl test2-1_u.pl | nkf -w 伊藤 東京都 10 800 800 10 [xxxxxxxx@dddddddddd Array]$
- 配列とは
[ 目次 ]
同じような目的で使用される複数の値を格納するのにそれぞれ変数を用意していると変数の数が無駄に増えてしまいます。例えば次の例を見てください。
my ($seiseki1, $seiseki2, $seiseki3); $seiseki1 = 80; $seiseki2 = 75; $seiseki3 = 69; print "$seiseki1\n"; print "$seiseki2\n"; print "$seiseki3\n";
3人分の成績を格納するために変数をそれぞれ用意して格納しています。3人であればこれでも構いませんが10人分の成績を管理しようとすれば変数も同じだけ必要となります。
このように同じような目的で使用される複数の値を管理する場合は配列を使うと便利です。配列は1つの変数名を使って複数の変数を管理することが出来ます。先ほどの例を配列を使って書き直すと次のようになります。
my @seiseki; $seiseki[0] = 80; $seiseki[1] = 75; $seiseki[2] = 69; print "$seiseki[0]\n"; print "$seiseki[1]\n"; print "$seiseki[2]\n";
配列を使った場合、配列として「seiseki」と言う名前を1つ用意し、必要な数の変数を変数名[インデックス]と言う形式で利用しています。
あまり配列を使った場合と使わなかった場合で何が違うのでしょうか。それは先ほどの例をさらに次のように書き換えることでよく分かります。
my @seiseki; $seiseki[0] = 80; $seiseki[1] = 75; $seiseki[2] = 69; for (my $i = 0; $i < 3; $i++){ print "$seiseki[$i]\n"; }変数名を別々に用意した場合は、各変数に対して1つ1つ処理を記述していくしかありませんが、配列を使った場合にはインデックス部分は数値として扱えますので繰り返し処理を組み合わせることで簡潔に処理が行えます。上記の例で言えば必要となる変数の数が100個になった場合でも画面出力部分は基本的に変わりがありません。
まったく別の目的で使用される複数の変数を配列としてまとめても意味はありませんが、今回のように同じ目的で複数の記憶領域が必要になるような場合には配列は大変便利です。
では簡単なプログラムで確認して見ます。
test3-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 配列とは # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my @seiseki; $seiseki[0] = 80; $seiseki[1] = 75; $seiseki[2] = 69; for (my $i = 0; $i < 3; $i++){ print "$seiseki[$i]\n"; }上記を「test3-1.pl」の名前で保存してから次のように実行して下さい。
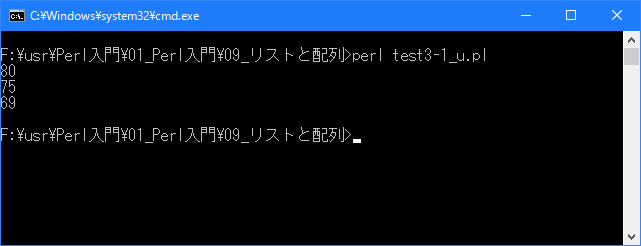
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxxx@dddddddddd Array]$ perl test3-1_u.pl | nkf -w 80 75 69 [xxxxxxxxx@dddddddddd Array]$
- 配列の宣言と要素へのアクセス
[ 目次 ]
それでは配列についてもう少し詳しく確認していきます。変数の場合と同じく配列を使用する場合にも宣言を行います。変数の場合はプレフィックス名して「$」を使用しましたが、配列の場合は「@」を使用します。
@配列名
例えば配列名として「name」を使った配列を宣言する場合は次のようになります。
my @name;
配列はリストの場合と同じく複数の値を管理しており、1つ1つは要素と呼ばれます。配列では要素はそれぞれ変数です。つまり配列では複数の変数を管理していると考えても構いません。変数はそれぞれ1つの値を管理できますので、配列では1つの値を管理できる変数をまとめて管理することにより複数の値を管理できるようになっています。
プログラミング言語によっては配列を宣言する時にいくつの要素を管理するのかを指定する言語もありますが、Perlの配列では、その配列が管理する要素数は自動的に拡張されたり縮小されたりします。
配列への値の格納と取得
配列に値を格納する場合は、配列が管理している複数の変数のどこか1つを指定して値を格納することになります。
配列の中に含まれる要素としての変数はインデックスと呼ばれる数値で区別されます。インデックスの先頭は0番目からとなっており、順に1番目、2番目、と続いていきます。配列の各インデックスに対応する領域に値を格納するには次の書式となります。
$配列名[インデックス] = 値;
配列に含まれる要素は1つ1つが変数ですので、インデックスを指定して要素に対して値を格納する場合は、プレフィックスが「@」ではなくて「$」となりますので注意して下さい。
my @seiseki; $seiseki[0] = 80; $seiseki[1] = 75;
上記の場合、まず配列「@seiseki」を宣言しています。そして配列の0番目の要素に数値の「80」を、1番目の要素に数値の「75」を格納しています。インデックスは括弧[]で囲んで指定します。
前述した通り、Perlの配列は要素を自動的に拡張します。その為、1番目の要素に値を格納するように記述すると自動的に1番目の要素が用意されます。例えば続けて2番目の要素利用するように記述してみます。
my @seiseki; $seiseki[0] = 80; $seiseki[1] = 75; $seiseki[2] = 65;
この場合は自動的に2番目の要素が用意されます。では連続していないインデックスを指定した場合はどうなるのでしょうか。
my @seiseki; $seiseki[0] = 80; $seiseki[1] = 75; $seiseki[2] = 65; $seiseki[5] = 92;
この記述自体はエラーではありません。この場合、5番目の要素が用意され数値の「92」が格納されます。ただし要素はインデックスに合わせて先頭から順に用意されていきます。2番目の要素まで使っていた状態の時に5番目の要素を使用すると、自動的に3番目と4番目の要素も用意されます。この自動的に作成された要素は初期化されていませんので要素の値は変数の場合と同じく未定義値「undef」となります。
要素に格納された値を取得する場合も変数の場合と基本的に代わりありません。変数の場合が「$変数名」だったのに対して配列の要素の場合は「$配列名[インデックス]」で参照できます。
my @seiseki; $seiseki[0] = 80; $seiseki[1] = 75; $seiseki[2] = 65; print "$seiseki[1]\n";
では簡単なプログラムで確認して見ます。
test4-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 配列の宣言と要素へのアクセス # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my @seiseki; $seiseki[0] = 80; $seiseki[1] = 75; $seiseki[2] = 69; $seiseki[5] = 91; print "$seiseki[5]\n";
上記を「test4-1.pl」の名前で保存してから次のように実行して下さい。
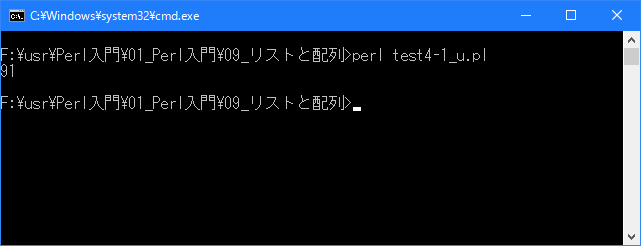
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@ddddddddddd Array]$ perl test4-1_u.pl | nkf -w 91 [xxxxxxxx@ddddddddddd Array]$
- 配列の初期化
[ 目次 ]
変数では宣言と同時に初期化をすることが出来ましたが、配列も同じように宣言と同時の初期化を行うことが出来ます。配列を宣言すると同時に格納する値を初期化するには次の書式を使います。
my @配列名 = (値1, 値2, ... , 値n);
配列に格納したい値をカンマで区切って並べ、全体を括弧()で囲んで指定します。
この値の指定方法はリストそのものです。つまり配列を初期化する時にはリストを指定するということになります。例えば次のように記述します。
my @name = ("伊藤", "加藤", "山田");初期化を行った場合には、リストの値がインデックス0から順に配列の要素に格納されていきます。よって次のように記述した場合とほぼ同じです。
my @name; $name[0] = "伊藤"; $name[1] = "加藤"; $name[2] = "山田";
配列の宣言時以外にリストを代入
配列を宣言する時以外にもリストを使って初期化することができます。
my @name; @name = ("伊藤", "加藤", "山田");この時注意して頂きたいのは既に配列にいくつかの要素が含まれている時にリストを使って初期化をすると、既にある要素は全てクリアされた上で新しく初期化されるということです。具体的な例で考えてみます。
my @num; $num[0] = 10; $num[1] = 9; $num[2] = 24; @num = (3, 7);
上記ではまず0番目から2番目までの要素に値を格納しています。その後で2つの値を使って初期化を行うと、0番目と1番目の要素の値だけが書き換えられて2番目の要素はそのままというわけではなく、配列がの要素が全てクリアされてから0番目と1番目の要素に値が格納されます。つまり2番目の要素は存在しなくなります。
もしも0番目と1番目の要素をリストを使って書き換えたい場合には、変数の場合と同じく次のように記述します。
my @num; $num[0] = 10; $num[1] = 9; $num[2] = 24; ($num[0], $num[1]) = (3, 7);
配列を一度リセットしたい場合は、空のリストである()を代入して下さい。
my @num; $num[0] = 10; $num[1] = 9; $num[2] = 24; @num = ();
では簡単なプログラムで確認して見ます。
test5-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 配列の初期化 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my @name = ("伊藤", "工藤", "山田"); $name[3] = "高橋"; $name[1] = "安藤"; for (my $i = 0; $i < 4; $i++){ print "$name[$i]\n"; }上記を「test5-1.pl」の名前で保存してから次のように実行して下さい。
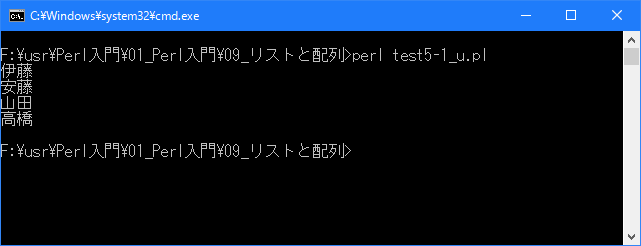
今回は配列を初期化した後で、要素を1つ追加し、既にある要素を別の値で書き換えています。
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Array]$ perl test5-1_u.pl | nkf -w 伊藤 安藤 山田 高橋 [xxxxxxxx@dddddddddd Array]$
- qw演算子
[ 目次 ]
配列の初期化を行う時に便利な演算子にqw演算子がよく利用されます。qw演算子は一覧の文字列を空白文字を区切りとして分割したリストを返してくれます。書式は次の通りです。
qw/ 対象となる文字列 /
対象となる文字列には例えば「東京 大阪 名古屋 福岡」のような文字列を指定します。
qw/ 東京 大阪 名古屋 福岡 /
この文字列を空白文字(スペースや改行、タブなど)を区切りとして文字列を分割します。そして分割された単語を要素とするリストを作成します。この時連続した空白文字は1つの区切りとして扱われます。つまり次のように記述した場合と同じです。
('東京', '大阪', '名古屋', '福岡')qw演算子で指定した文字列はシングルクォートで囲まれたものとして扱われますので文字列の中にエスケープシーケンス(一部除く)や変数などを記述しても特別な意味は持ちません。
複数の文字列をリスト形式ではなくqw演算子を用いて記述することで配列の初期化が簡単に記述できます。
my @pref = qw/ 東京 大阪 名古屋 福岡 /;
qw演算子の区切り文字
qw演算子では対象となる文字列がどこからどこまでなのかを示すために同じ記号を使って区切り文字とします(ここでの区切り文字は対象の文字列を区分するための空白文字のことではなく、対象の文字列がどこからどこからなのかを示すための区切り文字です)。
先ほどの例では区切り文字として「/」を使っていましたが、同じ記号であれば区切り文字はどんな文字でも構いません。また次の4つの場合は同じ記号でなくても使用できます。
qw( 対象となる文字列 ) qw{ 対象となる文字列 } qw[ 対象となる文字列 ] qw< 対象となる文字列 >区切り文字が対象の文字列の中に含まれている場合は「\」記号を使ってエスケープシーケンスを行うことが出来ます。
my @sample = qw/ abc d\/g eea /;
ただエスケープシーケンスを行うかわりに区切り文字を変更するほうが簡単な場合もあります。
my @sample = qw( abc d/g eea );
では簡単なプログラムで確認して見ます。
test6-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# qw演算子 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my @name = qw/ 伊藤 工藤 山田 /; for (my $i = 0; $i < 3; $i++){ print "$name[$i]\n"; }上記を「test6-1.pl」の名前で保存してから次のように実行して下さい。
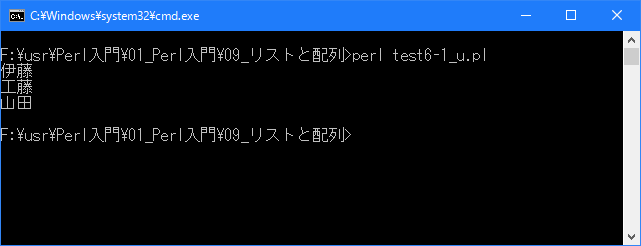
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Array]$ perl test6-1_u.pl | nkf -w 伊藤 工藤 山田 [xxxxxxxx@dddddddddd Array]$
- 範囲演算子
[ 目次 ]
リストを作成する時に数値を順番にならべるようなリストもよく使用されます。例えば10から15までの1つずつ増加するリストなどです。
my @count = (11, 12, 13, 14, 15);
このように整数の値で1つだけ増加していく連続した数値のリストを作成する場合には範囲演算子を使用すると便利です。書式は次の通りです。
(開始数..終了数)
リストの中で開始する数値と終了する数値を「..」で結んで記述します。例えば次のように記述します。
my @count = (11..15);
数値には小数点が含まれる数値を記述した場合は小数点以下が切り捨てられます。また増加する値は1と固定で、減算させることもできません。
範囲演算子はリストの中の1つの要素として扱えますので、他の要素や別の範囲演算子と組み合わせて記述すること可能です。
my @count = (1..5, 10, 15, 31..33);
これは下記のように記述した場合と同じです。
my @count = (1, 2, 3, 4, 5, 10, 15, 31, 32, 33);
では簡単なプログラムで確認して見ます。
test7-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 範囲演算子 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my @num = (10..14, 20); my $count = @num; for (my $i = 0; $i < $count; $i++){ print "$num[$i]\n"; }上記を「test7-1.pl」の名前で保存してから次のように実行して下さい。
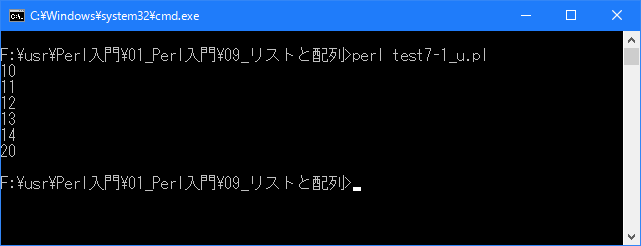
上記のサンプルでは配列の要素数を取得して使用しています。要素数の取得方法は「配列の要素数」と「配列の最後のインデックス」を参照して下さい。
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Array]$ perl test7-1_u.pl | nkf -w 10 11 12 13 14 20 [xxxxxxxx@dddddddddd Array]$
- 配列の要素数
[ 目次 ]
配列に現在含まれている要素数を取得する方法を確認します。要素数を取得するには配列を別の変数に格納することで取得できます。具体的には次のように記述します。
my @array = ("1月", "2月"); my $length = @array;配列を変数に格納することで配列の要素数が変数に格納されます。上記の場合であれば要素数として2が変数「$length」に格納されます。
注意すべき点としてはいったん変数に格納すると要素数が取得できますが、配列そのものを単に出力を行うと配列の要素数が出力されるわけではなく配列に含まれる要素が続けて出力されます。「@配列名」はあくまで配列全体を表しているのであって、「@配列名」が要素数そのものであるわけではありませんので注意して下さい。
なお配列の要素数を取得するには配列に含まれる最後の要素のインデックスから取得することも可能です。詳しくは「配列の最後のインデックス」を参照して下さい。
では簡単なプログラムで確認して見ます。
test8-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 配列の要素数 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my @array = ("1月", "2月"); my $length = @array; print "要素数 $length\n"; print @array; print "\n";上記を「test8-1.pl」の名前で保存してから次のように実行して下さい。
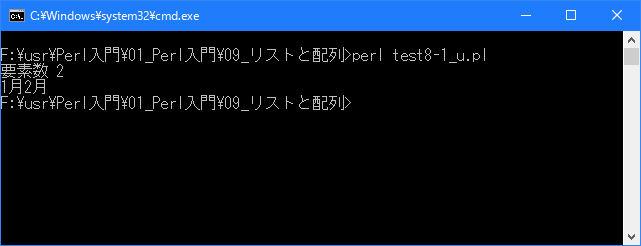
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Array]$ perl test8-1_u.pl | nkf -w 要素数 2 1月2月 [xxxxxxxx@dddddddddd Array]$
- 配列の最後のインデックス
[ 目次 ]
配列は複数の要素を持っていますが、最後の要素のインデックスを取得する方法を確認します。具体的には次のように記述します。
$#配列名
取得できる値は数値ですので、例えば最後の要素の値を書き換える場合は次のように記述できます。
my @str = ("1月", "2月", "6月"); $str[$#str] = "3月";この「$#配列名」は要素の最後のインデックスを参照しているわけではなく、最後のインデックスを管理しているものです。その為、「$#配列名」の値を変更すると配列に含まれる最後のインデックスが変更されます。例えば少ない数値を指定すれば、要素数そのものが減少します。増加すれば値が格納されていない要素が追加されます。
my @str = ("1月", "2月", "6月"); $#str = 1;上記のように設定すると、配列の最後のインデックスが「1」となりますので、インデックスが2の要素はなくなります。
なお配列のインデックスは0から開始されますので配列の要素数と最後の要素のインデックスは次のような関係となります。
要素数 = 最後のインデックス + 1
このように最後のインデックス数から要素数を計算することも出来ます。
では簡単なプログラムで確認して見ます。
test9-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 配列の最後のインデックス # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my @str = ("1月", "2月", "6月"); $str[$#str] = "3月"; for (my $i = 0; $i <= $#str; $i++){ print "$str[$i]\n"; } $#str = 1; for (my $i = 0; $i <= $#str; $i++){ print "$str[$i]\n"; }上記を「test9-1.pl」の名前で保存してから次のように実行して下さい。
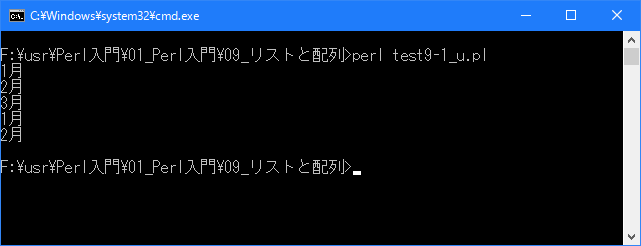
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Array]$ perl test9-1_u.pl | nkf -w 1月 2月 3月 1月 2月 [xxxxxxxx@dddddddddd Array]$
- 文字列中に含まれる配列の変数展開
[ 目次 ]
ダブルクオーテーションで囲まれた文字列の中に変数を記述すると、変数が記述された位置に変数に格納された値が展開されます。同じように文字列中に配列をを記述すると、記述された位置に配列が展開されます。
配列は複数の要素を持っていますので、展開される時は要素が順にスペースで区切られて展開されます。
my @name = ("加藤", "山田", "林"); print "登録されているのは @name です";文字列中の配列が展開が行われるのはダブルクオーテーションで囲まれた文字列だけです。シングルクオーテーションで囲まれた文字列の中に配列を記述しても、それは単なる文字として扱われるので配列とは認識されません。
my @name = ("加藤", "山田", "林"); print '登録されているのは @name です';上記では画面に「登録されているのは @name です」と言う文字列が出力されます。
展開時の配列名と文字列の区切り
変数の場合と同じく文字列中に記述された配列名の直後にアルファベットや数字やアンダーバーが記述されている場合は、どこまでが配列名なのか区別ができず意図しない動作となってしまいます。これを防ぐには配列名の直後は変数名として使用できない空白などの文字を記述して変数がどこからどこまでなのかを明確にするか、配列名を括弧{}で囲んで記述します。
my @name = ("加藤", "山田", "林"); print "Hello,@{name}san";このように記述することで文字列中の含まれる配列が「@name」であることを明確に表すことが出来ます。
特別変数「$"」
配列が展開される時、デフォルトではスペースで区切られて展開されますが、区切り文字は特別な変数「$"」に格納されている値が使用されます。デフォルトではスペースが格納されていますので、他の区切り文字を使って展開したい場合には変数「$"」に区切り文字を設定して下さい。
my @name = ("加藤", "山田", "林"); $" = ","; print "登録されているのは @name です";上記では画面に「登録されているのは 加藤,山田,林 です」と言う文字列が出力されます。
では簡単なプログラムで確認して見ます。
test10-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 文字列中に含まれる配列の変数展開 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my @name = ("加藤", "山田", "林"); print "登録されているのは @name です\n"; print '登録されているのは @name です'; print "\n"; $" = ","; print "登録されているのは @name です\n";上記を「test10-1.pl」の名前で保存してから次のように実行して下さい。
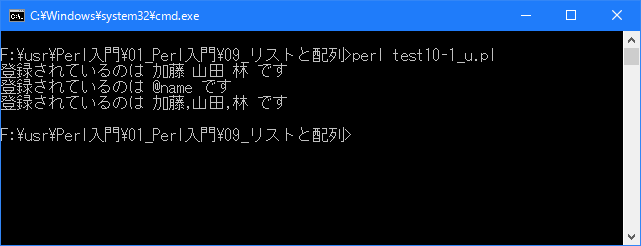
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Array]$ perl test10-1_u.pl | nkf -w 登録されているのは 加藤 山田 林 です 登録されているのは @name です 登録されているのは 加藤,山田,林 です [xxxxxxxx@dddddddddd Array]$
- 配列と繰り返し処理
[ 目次 ]
配列に含まれる要素を順に取り出して処理するといったことはよく行われる処理です。
繰り返し処理としては色々な方法があると思いますが主にはfor文またはforeach文を使います。まずfor文から試してみます。
for文を使う場合にはインデックスを0から最後のインデックスまで変化させて各要素を取り出します。例えば配列名が「@array」だった場合の最後のインデックスは「$#month」で表されますので次のような記述を行います。
my @array = ("東京", "大阪", "名古屋"); for (my $i = 0; $i <= $#array; $i++){ print "$array[$i]\n"; }foreach文の場合はインデックスを変化させる方法と要素を順に取り出す方法があります。インデックスを変化させる場合は次のように記述できます。
my @array = ("東京", "大阪", "名古屋"); foreach my $i(0 .. $#array){ print "$array[$i]\n"; }上記のような記述も可能ですが、foreach文の場合は指定されたリストの要素を順に取り出しますので次のように記述できます。
my @array = ("東京", "大阪", "名古屋"); foreach my $var(@array){ print "$var\n"; }最後の記述方法がよりシンプルとなりますが、場合によって使い分けて下さい。
では簡単なプログラムで確認して見ます。
test11-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 配列と繰り返し処理 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my @name = ("加藤", "山田", "林"); foreach (@name){ print "$_\n"; }上記を「test11-1.pl」の名前で保存してから次のように実行して下さい。
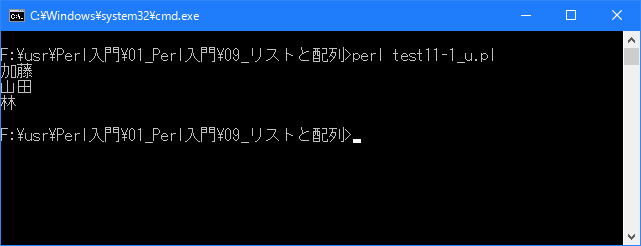
今回はforeach文の制御変数を省略しデフォルトの変数である「$_」を使用しました。
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Array]$ perl test11-1_u.pl | nkf -w 加藤 山田 林 [xxxxxxxx@dddddddddd Array]$
- リリースノート
[ 目次 ]- 2020/10/25 Ver=1.01 JDK_15 で確認
- 2017/03/03 Ver=1.01 初版リリース
- 関連ページ
[ 目次 ]