|
|
Perl正規表現の使い方 オプション修飾子 |
H.Kamifuji . |
- はじめに
オプション修飾子を指定することで記述したパターンがマッチする時の動作を変更することが出来ます。例えば大文字と小文字を区別せずにマッチさせる修飾子などが用意されています。ここではオプション修飾子の使い方を確認していきます。
当ページでは、Linux CentOS7 の Gnome で動作テストしています。
- 目 次
- オプション修飾子の種類と指定方法
[ 目次 ]
個々のオプション修飾子を確認する前に、オプション修飾子の指定方法と種類について確認しておきます。
オプション修飾子を指定する場合は次の書式となります。
m/パターン/修飾子
パターンマッチ演算子(m//)の2番目の「/」の次に修飾子を指定します。例えば「/i」修飾子を指定する場合は次のようになります。
m/パターン/i
またオプション修飾子は複数指定することが可能です。複数指定する場合は続けて記述して下さい。例えば「/i」修飾子と「/x」修飾子を同時に指定する場合は次のようになります。
m/パターン/ix
複数の修飾子が記述された時、修飾子が記述された順番は関係ありません。どのような順番で記述しても同じ結果となります。
なおオプション修飾子は「m//」演算子の他に、「s///」演算子や「qr//」演算子でも使用されます。
オプション修飾子の種類
オプション修飾子として用意されているものは次の通りです。
オプション修飾子 意味 /i 大文字と小文字を区別せずにマッチを行う /x パターンの中の空白やコメントを無視する /s メタ文字(.)が改行にマッチ /m 対象の文字列を複数行として扱う /o 正規表現のコンパイルを1回だけ行う /g 繰り返しマッチを行う /e 置換を行った結果を式として処理する
この中で「/g」演算子と「/e」演算子は正規表現による置換を行う際に使用されますので、置換の解説の箇所で詳しく確認します。
- 大文字と小文字を区別せずにマッチを行う(「/i」修飾子)
[ 目次 ]
「/i修飾子」を指定すると大文字と小文字を区別せずにマッチを行います。書式は次の通りです。
m/パターン/i
簡単な例で考えてみます。まず「/i」修飾子を使用しない場合です。
/Test/
上記の場合、マッチする文字列とマッチしない文字列は次のようになります。
○ Test × test × TEST × tesT
これに対して「/i」修飾子を指定した場合は次のように記述します。
/Test/i
上記の場合、マッチする文字列とマッチしない文字列は次のようになります。
○ Test ○ test ○ TEST ○ tesT
このように「/i」修飾子を指定した場合には大文字と小文字が区別されずにマッチされます。
では簡単なプログラムで確認して見ます。
test2-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# 大文字と小文字を区別せずにマッチを行う(「/i」修飾子) use strict; use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; print "パターン「/Test/」に対する結果\n\n"; &check1("Test"); &check1("test"); &check1("TEST"); print "\nパターン「/Test/i」に対する結果\n\n"; &check2("Test"); &check2("test"); &check2("TEST"); sub check1{ my ($str) = @_; if ($str =~ /Test/){ print "○:$str\n"; }else{ print "×:$str\n"; } } sub check2{ my ($str) = @_; if ($str =~ /Test/i){ print "○:$str\n"; }else{ print "×:$str\n"; } }上記を「test2-1.pl」の名前で保存してから次のように実行して下さい。
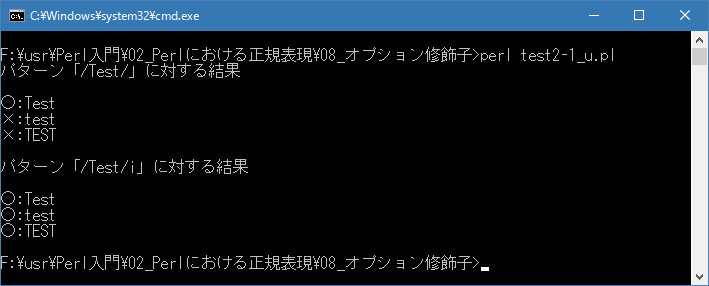
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Modifier]$ perl test2-1_u.pl | nkf -w パターン「/Test/」に対する結果 ○:Test ×:test ×:TEST パターン「/Test/i」に対する結果 ○:Test ○:test ○:TEST [xxxxxxxx@dddddddddd Modifier]$
- パターンの中の空白やコメントを無視する(「/x」修飾子)
[ 目次 ]
「/x修飾子」を指定するとパターンの中に記述された空白やコメントが無視されます。書式は次の通りです。
m/パターン/x
「/x」修飾子は複雑なパターンを分解して見やすく記述したり、コメントを記述したい場合に使われます。
次のようなパターンを例として考えてみます。
/((\d+)(yen))/
同じパターンに対して「/x」修飾子を指定した場合、パターン内の空白や改行は無視されるため次のように記述することが可能です。
/( (\d+) (yen) )/x
またパターン内のコメントも無視されるため(「#」から行末までがコメント)、次のようにコメントを記述しておくことが出来ます。
/( (\d+) #任意の数字を1回以上繰り返し (yen) #yenで終わる )/x
このように「/x」修飾子はパターンを見やすくしたり、パターン内の構成要素に対してコメントを記述しておく場合に使用されます。見た目だけの変更ですのでパターンにマッチするかどうかは違いがありません。
なお文字クラス内を除き空白は無視されてしまいますので、パターン内で空白を使用する場合は「\ 」のようにエスケープを行います。またコメントを表す「#」をパターン内で使用したい場合は同じく「\#」のようにエスケープを行います。
では簡単なプログラムで確認して見ます。
test3-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# パターンの中の空白やコメントを無視する(「/x」修飾子) use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; print "パターン「/((\\d+)(yen))/」に対する結果\n\n"; &check("2000yen"); &check("380yen"); &check("920en"); sub check{ my ($str) = @_; if ($str =~ /( ( \d #任意の数字 + #1回以上繰り返し ) ( yen #yenで終わる ) ) /x){ print "○:$str\n"; }else{ print "×:$str\n"; } }上記を「test3-1.pl」の名前で保存してから次のように実行して下さい。

Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Modifier]$ perl test3-1_u.pl | nkf -w パターン「/((\d+)(yen))/」に対する結果 ○:2000yen ○:380yen ×:920en [xxxxxxxx@dddddddddd Modifier]$
- メタ文字(.)が改行にマッチ(「/s」修飾子)
[ 目次 ]
「/s修飾子」を指定するとメタ文字(.)が改行にもマッチするようになります。書式は次の通りです。
m/パターン/s
メタ文字の「.」は改行にはマッチしませんでしたが、「/s」修飾子を指定すると改行にもマッチするようになります。(メタ文字「.」については「任意の一文字(.)」を参照して下さい)。
次のようなパターンを例として考えてみます。
/--.+--/
上記は「--」で始まり、任意の文字を表す「.」が1回以上繰り返された後で、「--」が再度現れるまでにマッチします。それでは次のような文字列を対象にマッチさせてみます。
ab -- log dot -- jp\n stone -- wat
この場合「--」で始まり任意の文字が続き「--」で終わる部分は次の箇所です。
ab -- log dot -- jp\n stone -- wat
次に同じパターンに対して「/s」修飾子を付けた場合です。
/--.+--/s
先ほどと同じ対象文字列に対してパターンをマッチさせてみます。
ab -- log dot -- jp\n stone -- wat
この場合「--」で始まり任意の文字が続き「--」で終わる部分は次の箇所です。
ab -- log dot -- jp\n stone -- wat
「/s」修飾子を付けた場合はメタ文字「.」が改行「\n」にもマッチするようになります。
では簡単なプログラムで確認して見ます。
test4-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# メタ文字(.)が改行にマッチ(「/s」修飾子) use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; print "パターン「--.+--/」に対する結果\n"; &check1("ab -- log dot -- jp\n stone -- wat"); print "\nパターン「--.+--/s」に対する結果\n"; &check2("ab -- log dot -- jp\n stone -- wat"); sub check1{ my ($str) = @_; if ($str =~ /--.+--/){ print "○:$str\n"; print "マッチする箇所:$&\n"; }else{ print "×:$str\n"; } } sub check2{ my ($str) = @_; if ($str =~ /--.+--/s){ print "○:$str\n"; print "マッチする箇所:$&\n"; }else{ print "×:$str\n"; } }上記を「test4-1.pl」の名前で保存してから次のように実行して下さい。
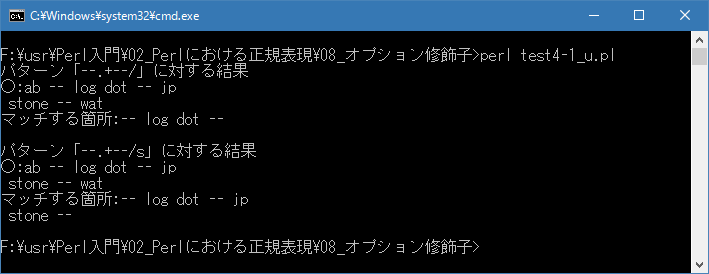
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Modifier]$ perl test4-1_u.pl | nkf -w パターン「--.+--/」に対する結果 ○:ab -- log dot -- jp stone -- wat マッチする箇所:-- log dot -- パターン「--.+--/s」に対する結果 ○:ab -- log dot -- jp stone -- wat マッチする箇所:-- log dot -- jp stone -- [xxxxxxxx@dddddddddd Modifier]$
- リリースノート
[ 目次 ]- 2020/10/25 Ver=1.01 JDK_15 で確認
- 2017/03/10 Ver=1.01 初版リリース
- 関連ページ
[ 目次 ]