|
|
Perl関数リファレンス 文字列に関する関数 |
H.Kamifuji . |
- はじめに
Perlの組み込み関数の中で文字列に関係する関数のリファレンスです。
当ページでは、Linux CentOS7 の Gnome で動作テストしています。
- 目 次
- length関数 文字列の長さを返す
- substr関数 文字列の部分文字列を取得又は置換
- split関数 文字列を指定のパターンで分割
- index関数 文字列の中に部分文字列が含まれるか検索し、最初の位置を返す
- rindex関数 文字列の中に部分文字列が含まれるか検索し、最後の位置を返す
- uc関数/ucfirst関数 文字列を全て大文字に変換/文字列の先頭の文字を大文字に変換
- lc関数/lcfirst関数 文字列を全て小文字に変換/文字列の先頭の文字を小文字に変換
- sprintf関数 指定した値を別途指定した書式指定文字によって変換し、作成された文字列を返す
- chop関数 文字列の末尾の文字を削除する
- chomp関数 文字列の末尾の改行文字を削除する
- hex関数 16進数を表す文字列を10進数に変換
- oct関数 8進数/16進数/2進数を表す文字列を10進数に変換
- chr関数 文字コードに対応する文字を返す
- ord関数 文字に対応する文字コードを返す
- リリースノート
- 関連ページ
- length関数 文字列の長さを返す
[ 目次 ]
「length」関数は対象となる文字列の長さを返します。
length length([EXPR])
文字列の長さを返します。文字列がUnicodeの場合には文字数を、そうでない場合には文字のバイト数となります。
パラメータ:
EXPR 対象の文字列
戻り値:
文字列の長さ
1番目の引数には対象となる文字列を指定します。省略された場合は変数「$_」が使用されます。取得できる文字の長さは日本語の場合には文字の数となりバイト数とはなりませんので注意して下さい。
※Unicode文字列の場合にバイト数を取得するには「bytes::length」を使用します。
具体的には次のように記述します。
print length("Hello"); print length("こんにちは");上記の場合はどちらも「5」を返します。
では簡単なプログラムで確認して見ます。
test1-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# length関数 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my $num; $num = length("Hello"); print "Hello = $num\n"; $num = length("こんにちは"); print "こんにちは = $num\n"; $num = bytes::length("こんにちは"); print "こんにちは = $num\n";上記を「test1-1.pl」の名前で保存してから次のように実行して下さい。

Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd String]$ perl test1-1_u.pl | nkf -w Hello = 5 こんにちは = 5 こんにちは = 15 [xxxxxxxx@dddddddddd String]$
- substr関数 文字列の部分文字列を取得又は置換
[ 目次 ]
「substr」関数は対象となる文字列の部分文字列を取得又は置換します。
1番目の引数には対象となる文字列を指定します。substr substr(EXPR,OFFSET[,LENGTH[,REPLACEMENT]])
対象の文字列の部分文字列の取得をします。REPLACEMENTを指定した場合には該当の部分文字列を新しい文字列で置き換えます。
パラメータ:
EXPR 対象の文字列
OFFSET 文字位置
LENGTH 文字の長さ
REPLACEMENT 置換する文字列
戻り値:
部分文字列
2番目の引数には文字列の中の位置を指定します。先頭の文字の位置は「0」です。位置に負の値を指定した場合、最後の文字を「-1」として最後から先頭に向かった移動した位置となります(「-2」の場合は最後から数えて2番目の文字)。
Morningと言う文字の文字位置 M o r n i n g -------------------- 0 1 2 3 4 5 6 -7 -6 -5 -4 -3 -2 -1
3番目の引数には文字の長さを指定します。文字の長さを省略した場合には最後の文字までとなります。また負の値を指定した場合には最後の文字を「-1」として先頭に向かって指定した長さだけ戻った位置にある文字の前の文字までとなります。
Morningと言う文字に対してsubstr(1, 2)とした場合は or Morningと言う文字に対してsubstr(1, -2)とした場合は orni M o r n i n g -------------------- 0 1 2 3 4 5 6 -7 -6 -5 -4 -3 -2 -1
4番目の引数には置き換える新しい文字列を指定します。置き換えの対象となるのは1番目から3番目の引数によって決定した部分文字列となります。この場合は1番目の引数そのものを置き換えるので、置きかえられた新しい文字列が格納できるように1番目の引数は文字列の値ではなく文字列が格納された変数を指定しなければなりません。
具体的には次のように記述します。
my $sub; $sub = substr("Morning", 2); print "$sub\n"; $sub = substr("Morning", -2); print "$sub\n"; $sub = substr("Morning", 1, 2); print "$sub\n"; $sub = substr("Morning", 1, -2); print "$sub\n"; my $targetstr = "Morning"; substr($targetstr, 1, -1, "ORNING"); print "$targetstr\n";上記の場合はどちらも「5」を返します。
では簡単なプログラムで確認して見ます。
test2-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# substr関数 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my $sub; $sub = substr("Morning", 2); print "substr(\"Morning\", 2) = $sub\n"; $sub = substr("Morning", -2); print "substr(\"Morning\", -2) = $sub\n"; $sub = substr("Morning", 1, 2); print "substr(\"Morning\", 1, 2) = $sub\n"; $sub = substr("Morning", 1, -2); print "substr(\"Morning\", 1, -2) = $sub\n"; my $targetstr = "Hello Satou"; print "old = $targetstr\n"; substr($targetstr, 5, 1, " Mr."); print "new = $targetstr\n";上記を「test2-1.pl」の名前で保存してから次のように実行して下さい。

Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd String]$ perl test2-1_u.pl | nkf -w substr("Morning", 2) = rning substr("Morning", -2) = ng substr("Morning", 1, 2) = or substr("Morning", 1, -2) = orni old = Hello Satou new = Hello Mr.Satou [xxxxxxxx@dddddddddd String]$
- split関数 文字列を指定のパターンで分割
[ 目次 ]
「split」関数は対象となる文字列を指定のパターンで分割します。
1番目の引数には文字列を分割するためのパターンを指定します。パターンは正規表現を使って指定します(正規表現について解説すると長くなってしまうため、パターンの指定方法は正規表現の解説を確認して下さい)。パターンを省略した場合は1個以上の空白文字(スペース、タブ、改行)を表す「/\s+/」を指定した場合と同じです。split split(/PATTERN/[,EXPR[,LIMIT]])
指定したパターンに従って文字列を分割します。分割した各文字列はリストとして取得します。
パラメータ:
/PATTERN/ 分割パターン文字列
EXPR 対象の文字列
LIMIT 分割の最大数
戻り値:
分割された文字列を要素とするリスト
2番目の引数には対象となる文字列を指定します。省略した場合にはデフォルト変数の「$_」が指定されたものとして扱われます。
3番目の引数には最大分割数を指定します。分割が指定した最大数に達すると、それ以上の分割は行われません。省略された場合は無制限となります。
具体的には次のように記述します。
my $targetstr = "My name is Gotou."; my @strlist = split(/ /, $targetstr);
上記の場合は「My」「name」「is」「Gotou.」の4つの要素に分割されます。
分割数の取得
「split」関数の戻り値をリストではなく値として受け取るように記述した場合は、分割された要素の数を取得します。例えば次のように使用します。
my $targetstr = "My name is Gotou."; my $count = split(/ /, $targetstr);
上記の場合は分割された個数である「4」が取得できます。
※ただし現在この使用方法は推奨されていないようですので注意して下さい。
では簡単なプログラムで確認して見ます。
test3-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# split関数 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my $target = "My name is Gotou."; print "$target\n"; print "\n空白で分割:\n"; my @list = split(/ /, $target); foreach my $parts(@list){ print "$parts\n"; } print "\n最大数2として空白で分割:\n"; @list = split(/ /, $target, 2); foreach my $parts(@list){ print "$parts\n"; }上記を「test3-1.pl」の名前で保存してから次のように実行して下さい。
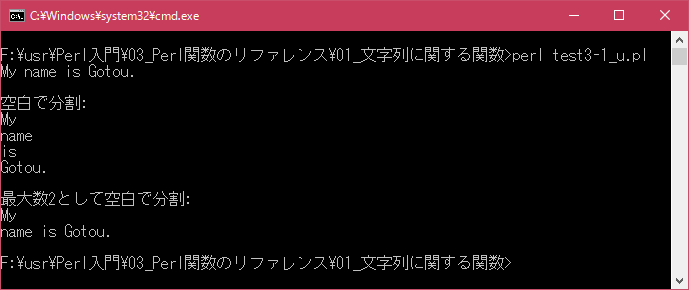
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd String]$ perl test3-1_u.pl | nkf -w My name is Gotou. 空白で分割: My name is Gotou. 最大数2として空白で分割: My name is Gotou. [xxxxxxxx@dddddddddd String]$
- index関数 文字列の中に部分文字列が含まれるか検索し、最初の位置を返す
[ 目次 ]
「index」関数は対象となる文字列の中に部分文字列が含まれるか検索し、最初の位置を返します。
※最後の位置を返すには「rindex関数」を使用します。
1番目の引数には対象となる文字列を指定します。index index(STR,SUBSTR[,POSITION])
指定した部分文字列が含まれるかどうかを検索し、含まれていた場合は最初に現れた位置を返します。
パラメータ:
STR 対象の文字列
SUBSTR 検索する部分文字列
POSITION 検索開始位置
戻り値:
見つかった場合は最初の位置、見つからなかった場合は-1
2番目の引数には検索する部分文字列を指定します。
3番目の引数には検索を開始する位置を指定します。省略した場合は先頭の文字となる「0」が指定されたものとして扱われます。
部分文字列が見つかった場合にはその位置を返します。見つからなかった場合は -1 が返されます。
Hamamatsu を対象に ma を検索する Hamamatsu --------- 012345678 この場合は2の位置に最初の ma が見つかるため 2 が返される
また検索開始位置を指定した場合は、指定した位置より後で最初に見つかった位置を返します。
Hamamatsu を対象に検索位置 3 から ma を検索する。 Ham|amatsu --------- 012|345678 この場合は4の位置に最初の ma が見つかるため 4 が返される
具体的には次のように記述します。
my $target = "Hamamatsu"; my $pos = index($target, "ma");
では簡単なプログラムで確認して見ます。
test4-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# index関数 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my $target = "Hamamatsu"; print "検索対象:$target, 検索文字:ma\n"; my $pos; $pos = index($target, "ma"); print "開始0, 位置:$pos\n"; $pos = index($target, "ma", 2); print "開始2, 位置:$pos\n"; $pos = index($target, "ma", 3); print "開始3, 位置:$pos\n"; $pos = index($target, "ma", 4); print "開始4, 位置:$pos\n"; $pos = index($target, "ma", 5); print "開始5, 位置:$pos\n";
上記を「test4-1.pl」の名前で保存してから次のように実行して下さい。
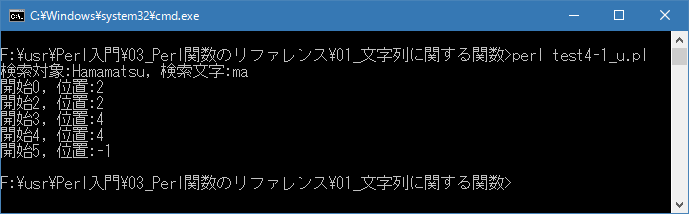
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd String]$ perl test4-1_u.pl | nkf -w 検索対象:Hamamatsu, 検索文字:ma 開始0, 位置:2 開始2, 位置:2 開始3, 位置:4 開始4, 位置:4 開始5, 位置:-1 [xxxxxxxx@dddddddddd String]$
- rindex関数 文字列の中に部分文字列が含まれるか検索し、最後の位置を返す
[ 目次 ]
「rindex」関数は対象となる文字列の中に部分文字列が含まれるか検索し、最後の位置を返します。
※最初の位置を返すには「index関数」を使用します。
rindex rindex(STR,SUBSTR[,POSITION])
指定した部分文字列が含まれるかどうかを検索し、含まれていた場合は最後に現れた位置を返します。
パラメータ:
STR 対象の文字列
SUBSTR 検索する部分文字列
POSITION 検索終了位置
戻り値:
見つかった場合は最初の位置、見つからなかった場合は-1
1番目の引数には対象となる文字列を指定します。
2番目の引数には検索する部分文字列を指定します。
3番目の引数には検索を終了する位置を指定します。指定した位置にある文字も検索対象に含まれます。省略した場合は最後の文字が指定され> たものとして扱われます。
部分文字列が見つかった場合にはその位置を返します。見つからなかった場合は -1 が返されます。
Hamamatsu を対象に ma を検索する Hamamatsu --------- 012345678 この場合は4の位置に最後の ma が見つかるため 4 が返される
また検索終了位置を指定した場合は次のように考えます。
Hamamatsu を対象に検索位置 5までの間で ma を検索する。 Hamama|tsu --------- 012345|678 この場合は4の位置に最後の ma が見つかるため 4 が返される
Hamamatsu を対象に検索位置 4までの間で ma を検索する。 Hamam|atsu --------- 01234|5678 この場合は4の位置に最後の ma が見つかるため 4 が返される 検索する部分文字列の先頭の文字が検索範囲に含まれていればOK
Hamamatsu を対象に検索位置 3までの間で ma を検索する。 Hama|matsu --------- 0123|45678 この場合は2の位置に最後の ma が見つかるため 2 が返される
具体的には次のように記述します。
my $target = "Hamamatsu"; my $pos = rindex($target, "ma");
では簡単なプログラムで確認して見ます。
test5-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# rindex関数 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my $target = "Hamamatsu"; print "検索対象:$target, 検索文字:ma\n"; my $pos; $pos = rindex($target, "ma"); print "終了末, 位置:$pos\n"; $pos = rindex($target, "ma", 5); print "終了5, 位置:$pos\n"; $pos = rindex($target, "ma", 4); print "終了4, 位置:$pos\n"; $pos = rindex($target, "ma", 3); print "終了3, 位置:$pos\n"; $pos = rindex($target, "ma", 2); print "終了2, 位置:$pos\n"; $pos = rindex($target, "ma", 1); print "終了1, 位置:$pos\n";
上記を「test5-1.pl」の名前で保存してから次のように実行して下さい。
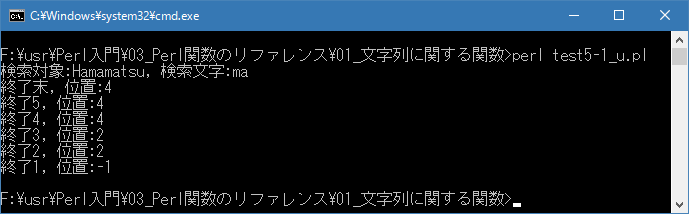
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd String]$ perl test5-1_u.pl | nkf -w 検索対象:Hamamatsu, 検索文字:ma 終了末, 位置:4 終了5, 位置:4 終了4, 位置:4 終了3, 位置:2 終了2, 位置:2 終了1, 位置:-1 [xxxxxxxx@dddddddddd String]$
- uc関数/ucfirst関数 文字列を全て大文字に変換/文字列の先頭の文字を大文字に変換
[ 目次 ]
「uc」関数は対象となる文字列を全て大文字に変換します。
※小文字に変換する場合は「lc関数/lcfirst関数」を使用します。
uc uc([EXPR])
対象の文字列を全て大文字に変換した文字列を返します。
パラメータ:
EXPR 対象の文字列
戻り値:
大文字に変換された文字列
1番目の引数には対象となる文字列を指定します。なお1番目の引数が省略された場合には変数「$_」が第一引数として使用されます。
具体的には次のように記述します。
my $target = "melon"; my $ucstr = uc($target);
この場合、結果として「MELON」が取得出来ます。
また先頭の文字だけを大文字に変換する場合には「ucfirst」関数を使用します。
1番目の引数には対象となる文字列を指定します。なお1番目の引数が省略された場合には変数「$_」が第一引数として使用されます。ucfirst ucfirst([EXPR])
対象の文字列の先頭を大文字に変換した文字列を返します。
パラメータ:
EXPR 対象の文字列
戻り値:
先頭の文字を大文字に変換された文字列
具体的には次のように記述します。
my $target = "melon"; my $ucfirststr = ucfirst($target);
この場合、結果として「Melon」が取得出来ます。
では簡単なプログラムで確認して見ます。
test6-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# uc関数/ucfirst関数 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my $target = "melon"; my $ucstr = uc($target); print "$target -> $ucstr\n"; my $ucfirststr = ucfirst($target); print "$target -> $ucfirststr\n";
上記を「test6-1.pl」の名前で保存してから次のように実行して下さい。

Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd String]$ perl test6-1_u.pl | nkf -w melon -> MELON melon -> Melon [xxxxxxxx@dddddddddd String]$
- lc関数/lcfirst関数 文字列を全て小文字に変換/文字列の先頭の文字を小文字に変換
[ 目次 ]
「lc」関数は対象となる文字列を全て小文字に変換します。
※大文字に変換する場合は「uc関数/ucfirst関数」を使用します。
lc lc([EXPR])
対象の文字列を全て小文字に変換した文字列を返します。
パラメータ:
EXPR 対象の文字列
戻り値:
小文字に変換された文字列
1番目の引数には対象となる文字列を指定します。なお1番目の引数が省略された場合には変数「$_」が第一引数として使用されます。
具体的には次のように記述します。
my $target = "MELON"; my $lcstr = lc($target);
この場合、結果として「melon」が取得出来ます。
また先頭の文字だけを大文字に変換する場合には「lcfirst」関数を使用します。
lcfirst lcfirst([EXPR])
対象の文字列の先頭を小文字に変換した文字列を返します。
パラメータ:
EXPR 対象の文字列
戻り値:
先頭の文字を小文字に変換された文字列
1番目の引数には対象となる文字列を指定します。なお1番目の引数が省略された場合には変数「$_」が第一引数として使用されます。
具体的には次のように記述します。
my $target = "MELON"; my $lcfirststr = lcfirst($target);
この場合、結果として「mELON」が取得出来ます。
では簡単なプログラムで確認して見ます。
test7-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# lc関数/lcfirst関数 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my $target = "MELON"; my $lcstr = lc($target); print "$target -> $lcstr\n"; my $lcfirststr = lcfirst($target); print "$target -> $lcfirststr\n";
上記を「test7-1.pl」の名前で保存してから次のように実行して下さい。

Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd String]$ perl test7-1_u.pl | nkf -w MELON -> melon MELON -> mELON [xxxxxxxx@dddddddddd String]$
- sprintf関数 指定した値を別途指定した書式指定文字によって変換し、作成された文字列を返す
[ 目次 ]
「sprintf」関数は指定した値を別途指定した書式指定文字によって変換し、作成された文字列を返します。
sprintf sprintf(FORMAT,LIST)
書式指定文字列で指定した方法に従って値を変換し、作成された新しい文字列を返します。
パラメータ:
FORMAT 書式指定文字列
LIST 変換される値のリスト
戻り値:
変換後の文字列
1番目の引数には値をどのように変換するのかを表す書式指定文字列を指定します。2番目の引数には変換される値を記述します。複数の値を指定する場合はカンマ(,)で区切って続けて記述します。
書式指定文字列の記述方法などの詳細な解説は「値の書式指定」を参照して下さい。
具体的には次のように記述します。
my $str = sprintf("[%#5o]", 30);この場合、変数「$str」に「[ 036]」と言う文字列が格納されます。
では簡単なプログラムで確認して見ます。
test8-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# sprintf関数 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my $str = sprintf("[%#5o]", 30); print "変換結果:$str\n"; my $shortstr = sprintf("%.3s", "September"); print "変換結果:$shortstr\n";上記を「test8-1.pl」の名前で保存してから次のように実行して下さい。

Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd String]$ perl test8-1_u.pl | nkf -w 変換結果:[ 036] 変換結果:Sep [xxxxxxxx@dddddddddd String]$
- chop関数 文字列の末尾の文字を削除する
[ 目次 ]
「chop」関数は対象の文字列の末尾の文字を削除します。
chop chop([VARIABLE])
対象の文字列から末尾の文字を削除します。
パラメータ:
VARIABLE 対象の文字列
戻り値:
削除された末尾の文字
1番目の引数には対象となる文字列を指定します。省略された場合は変数「$_」が使用されます。関数が呼び出されると対象の文字列の末尾の1文字が削除されます。戻り値には削除された末尾の文字が返されます。
対象となる文字列そのものに対して削除を行うため、引数には文字列が含まれる変数を指定する必要があります。
具体的には次のように記述します。
my $src = "abc"; chop($src);
この場合、変数「$str」に格納されていた「abc」から末尾の「c」が削除され変数「$str」に「ab」が格納されます。
「chop」関数は末尾の1文字を無条件で削除します。末尾の改行文字のみを削除したい場合は「chomp関数」を使用して下さい。
では簡単なプログラムで確認して見ます。
test9-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# chop関数 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my $src = "abcde"; print "削除前 : $src\n"; my $choppedstr = chop($src); print "削除後 : $src\n"; print "削除された文字 : $choppedstr\n";
上記を「test9-1.pl」の名前で保存してから次のように実行して下さい。

Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd String]$ perl test9-1_u.pl | nkf -w 削除前 : abcde 削除後 : abcd 削除された文字 : e [xxxxxxxx@dddddddddd String]$
- chomp関数 文字列の末尾の改行文字を削除する
[ 目次 ]
「chomp」関数は対象の文字列の末尾の改行文字を削除します。
chomp chomp([VARIABLE])
対象の文字列から末尾の改行文字を削除します。
パラメータ:
VARIABLE 対象の文字列
戻り値:
削除された末尾の文字数
1番目の引数には対象となる文字列を指定します。省略された場合は変数「$_」が使用されます。関数が呼び出されると対象の文字列の末尾が改行文字の場合に改行文字が削除されます。戻り値には削除された文字数が返されます。
対象となる文字列そのものに対して削除を行うため、引数には文字列が含まれる変数を指定する必要があります。
「chomp」関数は「chop」関数と似ていますが改行文字だけを削除したい場合に使用します。削除される改行文字は特別な変数「$/」に設定されている値によって異なります。
具体的には次のように記述します。
my $src1 = "abc\n"; chomp($src1); my $src2 = "abc"; chomp($src2);
この場合、変数「$str1」に格納されていた「abc」から末尾の「\n」が削除され変数「$str1」に「abc」が格納されます。また変数「$str2」に格納されている値には改行文字が含まれませんので、chomp関数を呼び出しても変数「$str2」に格納されている値に変化はありません。
※末尾の文字を無条件で削除する場合は「chop関数」を使用して下さい。
では簡単なプログラムで確認して見ます。
test10-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# chomp関数 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my $src1 = "abc\n"; my $src2 = "def"; my $src3 = "ghi\n"; print "削除前 : (start)$src1,$src2,$src3(end)\n"; my $num1 = chomp($src1); my $num2 = chomp($src2); my $num3 = chomp($src3); print "削除後 : (start)$src1,$src2,$src3(end)\n"; print "削除された文字数 : $num1,$num2,$num3\n";
上記を「test10-1.pl」の名前で保存してから次のように実行して下さい。

Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd String]$ perl test10-1_u.pl | nkf -w 削除前 : (start)abc ,def,ghi (end) 削除後 : (start)abc,def,ghi(end) 削除された文字数 : 1,0,1 [xxxxxxxx@dddddddddd String]$
- hex関数 16進数を表す文字列を10進数に変換
[ 目次 ]
「hex」関数は対象の文字列を16進数の数値と見なし、10進数の数値に変換します。
hex hex([EXPR])
対象の文字列を16進数の数値と見なし、10進数の数値に変換します。
パラメータ:
EXPR 対象の文字列
戻り値:
10進数の数値
1番目の引数には対象となる文字列を指定します。省略された場合は変数「$_」が使用されます。関数が呼び出されると、引数に指定した文字列を16進数の数値と見なし10進数の数値に変換して戻り値として返します。
引数に指定する文字列は「0x」付きであっても無くても構いません。
具体的には次のように記述します。
my $num1 = hex("3B"); my $num2 = hex("0xa4");この場合、「3B」は10進数の「59」に変換され、「0xa4」には10進数の「164」に変換されます。
※8進数や2進数として文字列を解釈する場合は「oct関数」を参照して下さい。また10進数から16進数に変換する場合は「sprintf関数」を参照して下さい。
では簡単なプログラムで確認して見ます。
test11-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# hex関数 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my $num1 = hex("3B"); my $num2 = hex("0xa4"); print "3B -> $num1\n"; print "0xa4 -> $num2\n";上記を「test11-1.pl」の名前で保存してから次のように実行して下さい。

Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd String]$ perl test11-1_u.pl | nkf -w 3B -> 59 0xa4 -> 164 [xxxxxxxx@dddddddddd String]$
- oct関数 8進数/16進数/2進数を表す文字列を10進数に変換
[ 目次 ]
「oct」関数は対象の文字列を8進数/16進数/2進数の数値と見なし、10進数の数値に変換します。
oct oct([EXPR])
対象の文字列を8進数/16進数/2進数の数値と見なし、10進数の数値に変換します。
パラメータ:
EXPR 対象の文字列
戻り値:
10進数の数値
1番目の引数には対象となる文字列を指定します。省略された場合は変数「$_」が使用されます。関数が呼び出されると、引数に指定した文字列を、文字列の形式に従って8進数/16進数/2進数の数値と見なし10進数の数値に変換して戻り値として返します。
引数に指定する文字列の先頭が「0」で始まる場合は8進数、「0x」で始まる場合は16進数、「0b」で始まる場合は2進数として解釈します。何も付いていない場合も8進数と解釈します。
具体的には次のように記述します。
my $num1 = oct("045"); my $num2 = oct("0xA4"); my $num3 = oct("0b1101"); my $num4 = oct("37");この場合、「045」は8進数と見なされ10進数の「37」へ、「0xA4」は16進数と見なされ10進数の「164」へ、「0b1101」は2進数と見なされ10進数の「13」へ、「37」は8進数と見なされ10進数の「31」へ変換されます。
※合わせて「hex関数」を参照して下さい。また10進数から8進数などに変換する場合は「sprintf関数」を参照して下さい。
では簡単なプログラムで確認して見ます。
test12-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# oct関数 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my $num1 = oct("045"); my $num2 = oct("0xA4"); my $num3 = oct("0b1101"); my $num4 = oct("37"); print "045 -> $num1\n"; print "0xA4 -> $num2\n"; print "0b1101 -> $num3\n"; print "37 -> $num4\n";上記を「test12-1.pl」の名前で保存してから次のように実行して下さい。

Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd String]$ perl test12-1_u.pl | nkf -w 045 -> 37 0xA4 -> 164 0b1101 -> 13 37 -> 31 [xxxxxxxx@dddddddddd String]$
- chr関数 文字コードに対応する文字を返す
[ 目次 ]
「chr」関数は文字コードに対応した文字を返します。
chr chr([NUMBER])
引数に指定した文字コードを対応する文字を返します。
パラメータ:
NUMBER 文字コード
戻り値:
文字
1番目の引数に変換する文字コードを表す数値を指定します。省略された場合は変数「$_」が使用されます。関数が呼び出されると、引数に指定した文字コードを対応する文字に変換して戻り値として返します。
具体的には次のように記述します。
my $charstr = chr(75);
この場合、文字コード「75」に対応した文字である「K」が取得できます。
※文字から文字コードを取得する場合は「ord関数」を参照して下さい。
では簡単なプログラムで確認して見ます。
test13-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# chr関数 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; for (my $chrno = 72; $chrno < 78; $chrno++){ my $charstr = chr($chrno); print "$chrno = $charstr\n"; }上記を「test13-1.pl」の名前で保存してから次のように実行して下さい。

Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd String]$ perl test13-1_u.pl | nkf -w 72 = H 73 = I 74 = J 75 = K 76 = L 77 = M [xxxxxxxx@dddddddddd String]$
- ord関数 文字に対応する文字コードを返す
[ 目次 ]
「ord」関数は文字に対応した文字コードを返します。
ord ord([EXPR])
引数に指定した文字列の先頭の文字に対応する文字コードを返します。
パラメータ:
EXPR 対象の文字列
戻り値:
先頭の文字の文字コード
1番目の引数に対象となる文字列を指定します。省略された場合は変数「$_」が使用されます。関数が呼び出されると、引数に指定した文字列の先頭の文字を対応する文字コードに変換して戻り値として返します。
具体的には次のように記述します。
my $chrnum = ord("ABC");この場合、文字列の先頭文字である「A」に対応した文字コードの「65」が取得できます。
※文字コードから文字を取得する場合は「chr関数」を参照して下さい。
では簡単なプログラムで確認して見ます。
test14-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
[xxxxxxxx@dddddddddd String]$ perl test14-1_u.pl | nkf -w C = 67 a = 97 l = 108 e = 101 n = 110 d = 100 a = 97 r = 114 [xxxxxxxx@dddddddddd String]$
上記を「test14-1.pl」の名前で保存してから次のように実行して下さい。

Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
- リリースノート
[ 目次 ]- 2020/10/25 Ver=1.01 JDK_15 で確認
- 2017/03/06 Ver=1.01 初版リリース
- 関連ページ
[ 目次 ]- Perl関数リファレンス
- Perl関数リファレンス 文字列に関する関数
事例を参照させていただきました。
- Perl関数リファレンス