|
|
Perl関数リファレンス ハッシュに関する関数 |
H.Kamifuji . |
- はじめに
Perlの組み込み関数の中でハッシュに関係する関数のリファレンスです。
※ハッシュに関しては「ハッシュ」を参照して下さい。
当ページでは、Linux CentOS7 の Gnome で動作テストしています。
- 目 次
- keys関数 ハッシュに含まれている全てのキーをリストの形で返す
[ 目次 ]
「keys」関数は対象となるハッシュに含まれている全てのキーをリストの形で返します。
keys keys(HASH)
全てのキーをリストの形で返します。
パラメータ:
HASH 対象のハッシュ
戻り値:
ハッシュに含まれるキーのリスト
1番目の引数には対象となるハッシュが格納されたハッシュ変数を指定します。
具体的には次のように記述します。
my %address = ( "鈴木" => "東京都千代田区", "山田" => "東京都葛飾区" ); my @keylist = keys(%address);
戻り値として取得できるリストを配列変数に格納しています。返されるキーのリストの要素がどのような順序で並んでいるかは分かりません。ハッシュでは各要素に順番は無いためです。
なお「keys」関数の戻り値を配列ではなく単なる変数に格納した場合は、ハッシュのキーのリストでは無くハッシュに含まれる要素の個数が格納されます。
my %address = ( "鈴木" => "東京都千代田区", "山田" => "東京都葛飾区" ); my $keycount = keys(%address);
※ハッシュに含まれる値のリストを取得するには「values関数」を参照して下さい。
では簡単なプログラムで確認して見ます。
test1-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# keys関数 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my %address = ( "鈴木" => "東京都千代田区", "山田" => "東京都葛飾区", "本田" => "愛知県名古屋市", "遠藤" => "大阪府堺市" ); my @keylist = keys(%address); my $keycount = keys(%address); print "要素数は $keycount です。\n"; for (my $i = 0; $i < $keycount; $i++){ print "$keylist[$i]\n"; }上記を「test1-1.pl」の名前で保存してから次のように実行して下さい。
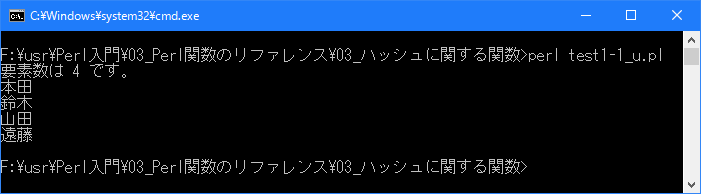
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Hash]$ perl test1-1_u.pl | nkf -w 要素数は 4 です。 山田 鈴木 本田 遠藤 [xxxxxxxx@dddddddddd Hash]$
- values関数 ハッシュに含まれている全ての値をリストの形で返す
[ 目次 ]
「values」関数は対象となるハッシュに含まれている全ての値をリストの形で返します。
values values(HASH)
全ての値をリストの形で返します。
パラメータ:
HASH 対象のハッシュ
戻り値:
ハッシュに含まれる値のリスト
1番目の引数には対象となるハッシュが格納されたハッシュ変数を指定します。
具体的には次のように記述します。
my %address = ( "鈴木" => "東京都千代田区", "山田" => "東京都葛飾区" ); my @valuelist = values(%address);
戻り値として取得できる値を配列変数に格納しています。返される値のリストの要素がどのような順序で並んでいるかは分かりません。ハッシュでは各要素に順番は無いためです。
なお「values」関数の戻り値を配列ではなく単なる変数に格納した場合は、ハッシュの値のリストでは無くハッシュに含まれる要素の個数が格納されます。
my %address = ( "鈴木" => "東京都千代田区", "山田" => "東京都葛飾区" ); my $valuecount = values(%address);
※ハッシュに含まれるキーのリストを取得するには「keys関数」を参照して下さい。
では簡単なプログラムで確認して見ます。
test2-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# values関数 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my %address = ( "鈴木" => "東京都千代田区", "山田" => "東京都葛飾区", "本田" => "愛知県名古屋市", "遠藤" => "大阪府堺市" ); my @valuelist = values(%address); my $valuecount = values(%address); print "要素数は $valuecount です。\n"; for (my $i = 0; $i < $valuecount; $i++){ print "$valuelist[$i]\n"; }上記を「test2-1.pl」の名前で保存してから次のように実行して下さい。
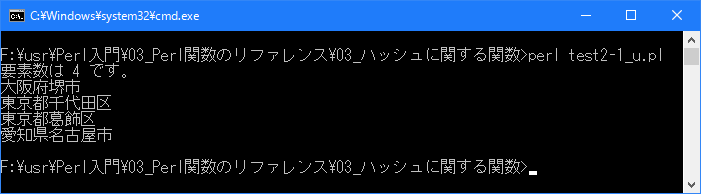
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Hash]$ perl test2-1_u.pl | nkf -w 要素数は 4 です。 東京都葛飾区 東京都千代田区 愛知県名古屋市 大阪府堺市 [xxxxxxxx@dddddddddd Hash]$
- each関数 ハッシュに含まれている要素を順に取り出す
[ 目次 ]
「each」関数は対象となるハッシュに含まれている要素を順に取り出します。
each each(HASH)
each関数が実行される度にハッシュに含まれる要素をキーと値のペアの形で順に取り出します。
パラメータ:
HASH 対象のハッシュ
戻り値:
キーと値のペアをリスト形式で取得
1番目の引数には対象となるハッシュが格納されたハッシュ変数を指定します。この関数は主に繰り返し処理と共に使用され、ハッシュに含まれる要素を順に取得したい場合に使用されます。
具体的には次のように記述します。
my %address = ( "鈴木" => "東京都千代田区", "山田" => "東京都葛飾区" ); while (my ($key, $value) = each(%address)){ print "key=$key, value=$value\n"; }each関数は実行される度にハッシュに含まれる要素を取り出します。イテレータ(反復子)を使い前回取り出した要素とは別の要素を順に取り出します。
今回のようにwhile文の条件式で要素の取り出しが行われると(実際には条件式のように値が必要な箇所でリストの代入が行われた場合)、条件式としてハッシュで取り出されていない要素の個数が評価されます。0以外の数値は全て真(true)ですのでこの繰り替えしはハッシュに要素が残っていない状態になると終了します。
では簡単なプログラムで確認して見ます。
test3-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# each関数 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my %address = ( "鈴木" => "東京都千代田区", "山田" => "東京都葛飾区", "本田" => "愛知県名古屋市", "遠藤" => "大阪府堺市" ); my @valuelist = values(%address); my $valuecount = values(%address); while (my ($key, $value) = each(%address)){ print "key=$key, value=$value\n"; }上記を「test3-1.pl」の名前で保存してから次のように実行して下さい。
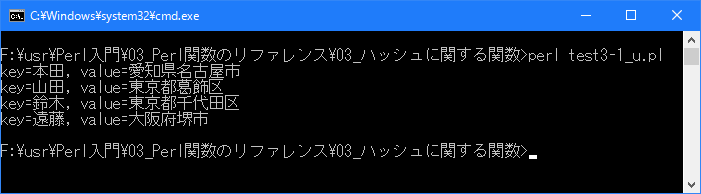
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Hash]$ perl test3-1_u.pl | nkf -w key=山田, value=東京都葛飾区 key=鈴木, value=東京都千代田区 key=本田, value=愛知県名古屋市 key=遠藤, value=大阪府堺市 [xxxxxxxx@dddddddddd Hash]$
- each関数 ハッシュに含まれている要素を順に取り出す
[ 目次 ]
「delete」関数は指定されたハッシュ要素を削除しキーと値を削除します。
delete delete(EXPR)
引数に指定されたハッシュ要素を削除します。キーと値のペアが削除されます。
パラメータ:
EXPR ハッシュの要素
戻り値:
キーに対応する値
1番目の引数には対象となるハッシュの要素を指定します。ハッシュの要素は「$ハッシュ名{キー}」で表されます。指定したキーが存在した場合、要素は削除され1つ減ります。
具体的には次のように記述します。
my %address = ( "鈴木" => "東京都千代田区", "山田" => "東京都葛飾区" ); delete($address{'鈴木'});指定したキーに該当するハッシュ要素が無かった場合は何も行わずエラーともなりません。
※ddelete関数は配列要素に対して使用できます。詳しくは「delete関数」を参照して下さい。
では簡単なプログラムで確認して見ます。
test4-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# delete関数 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my %address = ( "鈴木" => "東京都千代田区", "山田" => "東京都葛飾区", "本田" => "愛知県名古屋市", "遠藤" => "大阪府堺市" ); my $val = delete($address{'本田'}); print "削除された値:$val\n\n"; print "残っている要素\n"; while (my ($key, $value) = each(%address)){ print "key=$key, value=$value\n"; }上記を「test4-1.pl」の名前で保存してから次のように実行して下さい。
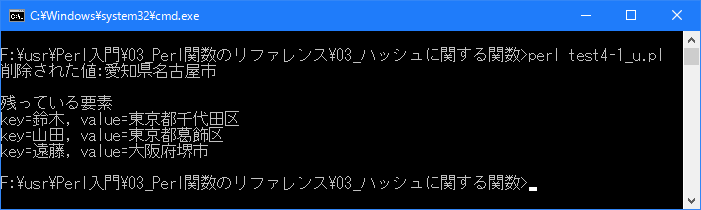
Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Hash]$ perl test4-1_u.pl | nkf -w 削除された値:愛知県名古屋市 残っている要素 key=山田, value=東京都葛飾区 key=鈴木, value=東京都千代田区 key=遠藤, value=大阪府堺市 [xxxxxxxx@dddddddddd Hash]$
- exists関数 指定したキーがハッシュに存在するかどうか確認
[ 目次 ]
「exists」関数は指定したキーがハッシュに存在するかどうか確認します。
exists exists(EXPR)
指定されたキーがハッシュに存在するかどうか確認します。
パラメータ:
EXPR ハッシュの要素
戻り値:
存在する場合は真(true)、そうでなければ偽(false)
1番目の引数には対象となるハッシュの要素を指定します。ハッシュの要素は「$ハッシュ名{キー}」で表されます。指定したキーが存在した場合、真(true)が戻り値として返されます。
注意すべき点はキーが存在するかどうかだけを見ている点です。キーに対応する値が未定義値であってもキーが存在すれば真(true)を返します。
具体的には次のように記述します。
my %address = ( "鈴木" => "東京都千代田区", "山田" => "東京都葛飾区" ); if (exists($address{'鈴木'})){ print "登録されています\n"; }では簡単なプログラムで確認して見ます。
test5-1.pl
サンプルプログラム
下記のサンプルを実行してみよう。
# exists関数 # use strict; use warnings; use utf8; binmode STDIN, ':encoding(cp932)'; binmode STDOUT, ':encoding(cp932)'; binmode STDERR, ':encoding(cp932)'; my %address = ( "鈴木" => "東京都千代田区", "山田" => "東京都葛飾区", "本田" => "愛知県名古屋市", "遠藤" => "大阪府堺市" ); my $name = "鈴木"; if (exists($address{$name})){ print "${name}さんは登録されています\n"; }上記を「test5-1.pl」の名前で保存してから次のように実行して下さい。

Linux 環境での実行結果は、下記です。シフトJIS で出力されるので nkf -w で UTF-8 に変換しています。
[xxxxxxxx@dddddddddd Hash]$ perl test5-1_u.pl | nkf -w 鈴木さんは登録されています [xxxxxxxx@dddddddddd Hash]$
- リリースノート
[ 目次 ]- 2020/10/25 Ver=1.01 JDK_15 で確認
- 2017/03/07 Ver=1.01 初版リリース
- 関連ページ
[ 目次 ]